RISC-V的HPC高端化之路还有多远?从CUDA谈起...
- 2025-07-21 10:14:26
过去我们一直认为,NVIDIA现在真正看重的,是基于Arm的生态:
虽然老黄此前在采访中多次提到,之所以推Grace/Vera这类基于Arm指令集的CPU,主要原因是市场上没有对应的同类产品;但我们始终认为,这就是在AI HPC领域,NVIDIA明显偏向Arm,且未来有概率抛弃x86的体现——要不然为什么市场宣传工作做得那么足的NVL机柜(如GB300 NVL72)都是基于Arm的?
属于Arm的AI HPC时代似乎已经全面来临了。
但有两件事最近让我们改变了看法。其一是今年Computex上,老黄在主题演讲中宣布推出NVLink Fusion服务,下游客户可以根据自己的需要,在NVLink连接的系统中加入自己的AISC加速器,甚至可以换用自己的CPU,基于chiplet和NVLink C2C——是不是还挺意外的?虽然很容易想见,这也是为了加强NVIDIA HPC/AI生态粘性。
最近的RISC-V中国峰会2025之上,NVIDIA副总裁Frans Sijstermans还在主题演讲中补充说,NVLink Fusion现在也支持客户用自己的RISC-V CPU(系统中基于NVLink C2C连接到NVIDIA GPU)——不知Arm对此事作何感想。
其二,同样是Frans在峰会论坛上提到的,CUDA on RISC-V已成——也就是说,现在CUDA生态可以跑在RISC-V处理器平台。在此之前,CUDA驱动仅支持x86与Arm处理器;而现在RISC-V处理器也能作为主CPU,搭配NVIDIA显卡跑CUDA了。
这是个什么概念呢?即便抛开AI不谈,CUDA驱动大量行业的HPC加速库一抓就有一大把,比如用于半导体制造光刻的cuLitho、气候分析的Earth-2、数值计算的cuPyNumeric、量子计算的CUDA-Q......未来它们都有可能跑在RISC-V平台上。
这么一来,本文标题的答案似乎已经有了:论HPC和AI,现在哪里还有人比NVIDIA更夯的?RISC-V的AI/HPC之路不是已经完成了吗......
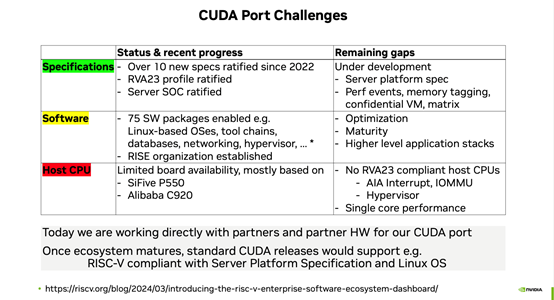
当然,目前面向RISC-V生态的CUDA移植工作,看起来还是相对初级的,如上图所示——NVIDIA着眼这件事似乎也挺久了;实际现在真正达成RVA23 Profile兼容的RISC-V主CPU都还没有,NVIDIA支持的板子及平台也很少。Frans表示,虽然还有很多工作要做,也还远远没有软件包发行版做到开箱即跑在RISC-V CPU上,但进展已经相当不错——还在跟合作伙伴、RISC-V生态持续合作。
借着这篇文章,以及在今年RISC-V中国峰会上的所见所闻,我们来着重看看RISC-V走向AI HPC为代表的高端市场之路,到底走到了哪一步——即便CUDA on RISC-V就已经让我们讶异于RISC-V在该领域的发展之神速了,但这其实也不是真正体现RISC-V生态发展“神速”之所在...

算能展位的RISC-V计算服务器SRA1-20
“高性能”已经不是重点
这里我们所说的HPC应用是相对广义的HPC高性能计算,它更多的相对于嵌入式应用——如TSMC就习惯在财报中,将个人PC也归于HPC类。电子工程专辑从2022年起就在追踪RISC-V于HPC领域内的发展情况。
不过和往年的RISC-V产业论坛或峰会有所不同,今年的RISC-V中国峰会主论坛演讲,已经有过半演讲人在谈HPC。而且和过去两三年有显著差异的是,这些演讲者几乎都已经不再将重点放在自家RISC-V产品的性能参数上。因为大部分人几乎都默认了RISC-V指令集做到硬件指标的高性能不存在任何问题。
孟建熠(知合计算CEO)在谈性能问题时给出了下面这张图。这张图的横轴为核心主频,纵轴为每GHz的SPECint2017基准成绩——位处“高性能俱乐部”的处理器核心,主流当然还是来自x86和Arm阵营。孟建熠认为,RISC-V与Arm瞄准单位性能(每GHz性能)的路子一致,“我们自己的实践是,RISC-V核也完全能做到2.5(/GHz)以上,没有疑问。”


▲ 阿里达摩院除提到玄铁C930达到15/GHz的核心性能,也列出了现在比较有名的RISC-V高性能设计,及其已经触及的核心性能水平...
包云岗(中国科学院计算技术研究所副所长,中国开放指令生态(RISC-V)联盟秘书长,北京开源芯片研究院首席科学家)也在谈香山开源高性能计算子系统时说,南湖和昆明湖现阶段分别已经达到Cortex-A76与Neoverse N2的水平——2024昆明湖(v2)RISC-V IP核做到了15/GHz(SPECCPU 2006),“加上编译优化可以做到18/GHz”,最终“虽然7nm(3GHz)工艺得到的面积与功耗评估数据相比N2仍有差距,但差距已经很小”。
Tenstorrent则在今年的主题演讲中说,自家的Ascalon核心达成了“与最新AMD Zen 4/5差不多的性能”(标称>20 SPEC2006int/GHz),计划“未来2、3年,Tenstorrent会把Ascalon的性能每年提升10%。”练维汉(Tenstorrent首席架构师)谈到,“我们还有一支团队在做更高性能的CPU”,PPT中提到该核心代号Callador(下图),每GHz的SPECint2006性能据说可以做到35分(3.5 SPECint2017/GHz),“是全世界最快的CPU”,虽然预期该核心的发布时间要等到2027年。

只不过这些数字,在他们的演讲中所占比重都极低,仿佛这根本不是个特别值得去提的问题了。即便不说RISC-V开放、可扩展之类的固有特点,在技术相关的话题上,演讲者谈的都是扩展指令集、RVA23 Profile(RISC-V International)、片上网络(开芯院)、UEFI + ACPI(高通)、binary translation(二进制转义),乃至从系统层面看AI性能优化(中兴微电子),无论这些东西是否已经落地,问题探讨的高度显然已今非昔比。
走向HPC的两个基础思维与方向
我们认为,从高抽象层级体现RISC-V今非昔比还有两个重要标志。一是主论坛圆桌环节,戴伟民(峰会主席、上海开放处理器产业创新中心理事长)再度提到有关指令的自主、可控、繁荣三大要素——这是他在近两年的RISC-V圆桌活动上基本都会去谈的,包括x86是不自主、不可控,但生态繁荣的;Arm是可控、但不自主、生态也繁荣的;还有诸如MIPS、Alpha等是自主、可控,但不繁荣的。
现在唯有RISC-V是自主、可控,且繁荣的。有所不同的是,戴伟民在自主、可控、繁荣之外,为RISC-V新增了一个形容词——“创新”,“RISC-V是可以创新的”。我们理解RISC-V可“创新”的基础,就在于指令集本身的开源、开放属性,指令集扩展、架构基于特定应用的裁剪,乃至适配于现在流行的AI等等应当都可以视作“创新”——但这不是全部,有关“开放”特性,后文还将着重谈到。
另一个大概可视作RISC-V今非昔比、未来要走向主流HPC的演讲,应该是Leendert van Doorn(高通资深副总裁)去谈随着RISC-V芯片最终要做规模与算力扩展(scaling),那么参与者们势必要拥抱平台与生态思维(platform and ecosystem mindset)。啥意思呢?
Leendert本人有着构建Windows Server on Arm,以及让Azure云跑在Arm平台之上、包括移植虚拟机、存储技术栈的充足经验。他基于自己在服务器从x86迁往Arm的经历,给予RISC-V走相同路子提出了两个建议——虽然其实数据中心服务器只是广义HPC应用的一类,但我们认为其中也依旧有相关各类HPC应用的相通性。

有没有想过,拯救者掌机里头也有RISC-V芯片?虽然不是主要负责图形计算,但这里头的CH32V303微控制器基于青稞RISC-V4F内核,用于手柄功能实现,包括按键、霍尔扳机、摇杆、陀螺仪、RGB灯效控制等…
我们总结Leendert提的建议主要有以下几点:他认为开放标准和社区合作,是RISC-V本身已有的优势,尤其指令集的矩阵乘、AI相关的扩展,以及不同版本的Profile配置,令该指令集及生态能够以相对一致的步调适配于各类不同应用;
(1)在此基础上,首先要有平台思维。除了CPU之外,还要考虑加速器、IO控制器、总线、固件与软件,各种平台功能标准化,以及充分利用现有生态(如复用已经得到证明的标准)、裁剪后的平台Profile。
有关“平台思维”,我们认为颇具代表性的一点是在平台功能标准化问题上,他特别举例提到了UEFI + ACPI。绝大部分了解Arm早年从嵌入、移动,走向桌面、服务器领域的读者应该知道,其古早的嵌入式基因——尤其依托device tree令其在HPC领域一度难以前行。“这不是个相关于技术使能(technical enablement)的问题,而相关于我们走向的平台与生态,如何以最小阻力构建起生态,这对平台真的很重要。”
(2)要有生态系统思维。移植compiler、各类基础组件,移植SDK等操作是漫长的过程,也均为寻常。应用软件的“长尾(long tail)”特性,令任何很小的兼容问题都足以致命——Leendert表示,即便Arm在服务器市场做了这么久,其生态的成熟性依旧远不及x86。
所以针对“生态系统思维”,他提到的一个重要建议是尽早去搞binary translation,以及诸如ARM64EC这样的混合解决方案(原生与模拟代码混合运行)。Binary translation要做两套,分别是从x86→RISC-V,和Arm→RISC-V;要做两套是因为“Arm本身其实也没有完全为服务器做好充分准备”。
“我其实真的很希望,当初在做Azure相关工作的时候,我们能更早就去做binary translation。因为它的确能够帮助降低移植成本。”虽然他也赞同binary translation并非万能药,尤其对JIT动态生成代码类型的应用;但作为需要软硬件共同协作,尤其也需要硬件设计辅助的方案,binary translation仍然是必须的。

RISC-V指令集的“创新”
Leendert谈的更多还是发展“建议”,可能在很多人看来不够“落地”,或者说他没有去谈“平台思维”与“生态系统思维”在RISC-V生态内的落实成果;但将RISC-V视作一个生态,而不是单纯的ISA指令集,恐怕的确是RISC-V在“向上”过程中的,软硬件两个方向上需要去考虑生态完善的基本思路。
而且这样的话题探讨高度,对比2、3年前RISC-V参与者探讨的内容,是不是的确体现了RISC-V的今非昔比?不过我们当然还是期望基于“平台”和“生态”两个角度,谈点落地和更具现实意义的内容:
虽然基于峰会主论坛演讲,我们无法系统性概括RISC-V平台及各类功能标准发展情况,但从偏平台或硬件的角度来看,能具体反映RISC-V指令集发展情况的应该就是profile配置和扩展指令更新了。Andrea Gallo(RISC-V国际基金会CEO)特别提到了RVA23 profile。RVA23指明了一系列强制和可选的新特性和扩展——虽然通常这类profile的推进很大程度上就是为了确保不同RISC-V实施方案的软件相容性,属于处理器“基线特性集(baseline feature set)”般的存在。

Andrea表示RVA23是经过了长时间的开发、审视、认证流程的,毕竟它需要适用于大量应用、系统软件生态。RVA23包含不少得到批准的ISA扩展,比如说针对并行数据处理(包括AI/ML)的矢量扩展,针对虚拟化的hypervisor扩展,针对数值计算的某些浮点指令,用于代码密度的压缩指令,面向系统级性能的cache与内存管理扩展等...
常被人称作RISC-V之父的Krste Asanović(RISC-V国际基金会首席架构师,SiFive首席架构师,加州大学伯克利分校研究生院名誉教授)也在峰会主题演讲中详细谈到了目前RISC-V Profile的进展情况,除了去年10月刚刚批准的“RVA23作为RISC-V目前最重要的profile”,“是非常完整、具备竞争力的特性集”,“今年末到明年会有不同的RVA23硬件解决方案出现”,更重要的是“RISC-V仍在走向未来”。
规划中的下一个小更新是RVA23p1,只会增加可选项——而且未来每年可能都会有1-2次小版本更新发布。Krste补充说,小版本更新的可选项都是为了给下一个大更新RVA30强制特性做准备——RVA30预计会在2-3年后发布(not expected for another 2-3 years)。
除了Profile更新,还会有一些额外的扩展来完善RISC-V面向不同应用的需求,比如说安全扩展Supervisor-mode PMP(Physical Memory Protection)——去年末电子工程专辑发布的《汽车动力与底盘MCU市场现状研究报告》还特别提到RISC-V在高安全需求的车规MCU应用面临的安全性挑战。现在这些问题就指令集层面,正在逐渐被解决。可见RISC-V指令集发展之迅速。
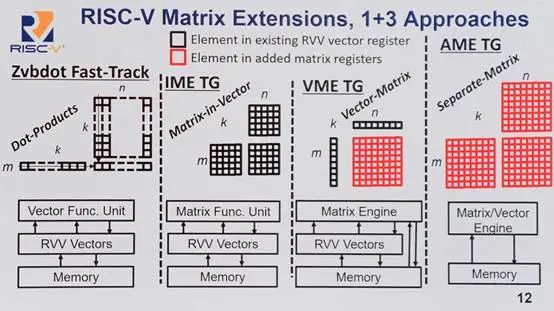
▲ RISC-V矩阵扩展的1+3种方法,面向不同类型的系统;部分涉及到是否使用现有RVV矢量寄存器或新增矩阵寄存器;应当是现有资源复用、专用扩展性,以及吞成本与吞吐权衡的差别——Krste说适配现在和将来的各种AI需求...
还有DSP扩展(RISC-V P扩展,矢量DSP扩展)、>32b的长指令支持(Krste说固定32b指令格式对RISC-V长期发展而言是不利的),以及峰会上不止一个人在谈的Matrix Extensions矩阵扩展——毕竟现在都流行说RISC-V是AI时代最有潜力的指令集——可惜我们没能参加次日的人工智能分论坛,有兴趣的读者可以去找找Krste在分论坛上就RISC-V矩阵扩展的技术向报道。
“合作”——另一个角度看“开放性”
有关可扩展性给到RISC-V用于高性能计算的巨大动力,实则也是很多嘉宾谈到的关键话题,比如阿里达摩院玄铁负责人就特别花篇幅去谈了在通用计算之外,RISC-V可做的扩展囊括“大位宽vector”,“Matrix”,乃至DSA机制。
玄铁就用上了“RISC-V大位宽vector引擎”,被称为玄铁TITAN(512-4096bits Vlen硬件可配置);以及“兼容RISC-V AME扩展”的玄铁TPE(Tensor Processing Engine),令GEMM算力利用率提升了2-3x;以及基于DSA扩展接口,增加定制DSA......玄铁C930应当就是囊括了上述三个项目的处理器。
这颗处理器事实上也是我们日常在写RISC-V相关优势时,反复提到的RISC-V开放、灵活基本逻辑的体现,是x86和Arm这样的指令集做不到的;也是戴伟民在圆桌环节所说可做指令集“创新”的关键构成。不过我们似乎忽略了一个更重要的事实:与“开放”“灵活”更相关的一个关键词其实是“合作”。这就要谈到Tenstorrent今年演讲的主题了。

▲ RISC-V之父Krste Asanović;多说一句...能在一场活动上同时看到Krste Asanović和Jim Keller,那也是相当难得...
Jim Keller(Tenstorrent首席执行官)的演讲主题基本就是围绕着Tenstorrent做AI处理器,选择RISC-V的原因就在于RISC-V的开放性。从底层的Tenstorrent AI引擎是基于开放的RISC-V,往上层Tenstorrent的AI软件也是开放的(包括AI compiler、AI kernel与runtime环境),AI模型绝大部分是开放的,PyTorch, Jax, Triton也都是开放的标准。
RISC-V使能AI显得理所应当,“开放的RISC-V加上开放的软件,最终会成功”。在Jim看来,“创新、分享才是进步的动力。”不过这不是这套逻辑的全部。练维汉针对Tenstorrent自下至上都采用开放解决方案的逻辑主要谈到了两点:
(1)AI时代的芯片设计面临多样性,未来AI将广泛应用,需要有大量不同的架构、设计来解决问题;(2)走向“AI民主化”,让每个人都能用上AI技术,就需要降低AI使用的成本,降低AI推理、AI硬件的成本。要同时满足这两点,就需要使用开放、开源的工具,由所有社区内的参与者一起合作,组建与完善生态。
这个理念当然不能说有多新,包括Intel之类的市场参与者在对抗NVIDIA之时的基本逻辑差不多也是如此,只不过大部分参与者都没有Tenstorrent对整个技术栈的“开放”态度那么激进——开放式硬件(RISC-V处理器,及可扩展互联架构)、开放式软件栈(Metal、神经网络、MLIR、Forge),以及OCA(开放式chiplet架构)——以此解决(1)需求多样化,(2)开发和使用成本高的问题。“我们所有的东西都是开源的。”

来源:OCA whitepaper
这里简单谈谈Tenstorrent打造的OCA(Open Chiplet Architecture)标准。关注HPC的读者对chiplet、先进封装应该不会陌生,电子工程专辑对此有过反复撰文。对于芯片开发而言,设计可复用、开发成本更低、可灵活组合、异构,可满足多样化需求均为chiplet技术的优势。而OCA标准据说是Tenstorrent“研究了两年半”的方案。
这套标准自物理层到软件层共5个层级,覆盖软硬件全技术栈,“最大限度采用现有行业标准”,据说任何一个层级都“无厂商锁定”,可搭配组合来自不同技术方案与chiplet。“企业组织可以专注于自己的核心价值设计”,不需要做自己不擅长的部分。练维汉还特别列举了针对软件定义汽车芯片,组合不同来源的chiplet,构成融合CPU、AI加速器、娱乐系统等在内的各类组成部分,应对各种需求,覆盖L1-L4各种自动驾驶需求。
“大家合作,共同开发相融的芯片,组合出能够满足未来AI芯片需求的产品”,以更低的成本完成“AI的普及化”,达到“开放生态+极致性价比=行业变革”的目标。
这套逻辑本来就是chiplet与先进封装技术在开启之初就期望达成的目标——虽然当时我们说它有些过于理想;OCA要真正达到商业上的成功也有待市场验证。不过此处谈到的“合作”的确也是RISC-V作为开放生态的巨大优势之一:且不仅在chiplet、芯片设计层面,还在软件和开发生态上。
峰会上谈论“合作”这一关键词的企业当然远不止Tenstorrent一家。比如包云岗就谈到,基于开源的联合研发,合作企业在昆明湖开发过程中贡献了超过1/3的bug发现与修复;v3也有更多企业共同参与联合研发……知合计算的演讲更是不下10次提到“合作”二字……
我们认为,“合作”和“创新”这两个词基本就是本届RISC-V中国峰会的关键词。
正是因为有足够多的参与者,在软硬件上为生态添砖加瓦,才让RISC-V有了这么快的发展速度,乃至相较Arm, x86这些现有强者具备更强的创新能力,形成技术与市场的竞争力,也才有机会让RISC-V真正为HPC更多应用所用,而不是仅凭技术自主性或地缘政治需求。
将在HPC市场“三分天下”
Krste在演讲开场特别提到,RISC-V并不是个特别针对AI的ISA,也不是针对HPC、networking等应用的,“这是个能做一切的ISA,RISC-V将会是比任何ISA应用范围更广的指令集”。PPT上写的“attacking each vertical”,这格局就比我们在这儿探讨RISC-V走向HPC和AI高多了。
不过今年峰会现场好几名嘉宾都提到了RISC-V必然会达成“三分天下”。比如Andrea Gallo在演讲开场就援引SHD Group的数据,提到预计到2031年,RISC-V SoC芯片出货量会超过200亿,SoC芯片市场渗透率超过了25.7%。
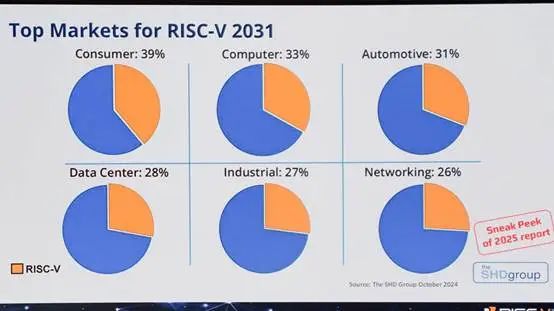
届时,RISC-V在消费、计算机、汽车、数据中心、工业、networking六个领域的市场份额则分别如上图。不过这份数据泛化了SoC所指——形势也未必已经这么乐观了。比如说现场至少2名嘉宾都提到了NVIDIA的RISC-V芯片年出货量超过10亿——实际上NVIDIA的确在现有GPU之中用上了定制设计的RISC-V控制器,主要用于计算资源、电源、显示与安全等相关的管理工作,它很难被视作GPU主体。
不过有兴趣的读者可以去关注NVIDIA在这部分RISC-V核心上下的工夫的确也还是不小的,去年的RISC-V Summit上,NVIDIA就提到现在NVIDIA就开发了至少3种RISC-V控制器核心,且在控制器中堆了10-40个这样的核心。
阿里达摩院玄铁负责人说RISC-V“在嵌入式领域,三分天下的局面已经形成”,“现在我们要往HPC方向上发展”,“我相信基于这样的趋势,RISC-V在各领域都会三分天下”,乃至“在未来15年内,在高性能、大算力领域称为统治级架构(dominant architecture)”。
有关RISC-V生态建设进度,受限于篇幅,峰会上的不少内容是本文未曾涉及的:比如说中兴微电子甚至已经开始站在系统层面,从服务器集群与架构优化的高度去谈RISC-V对于AI HPC的价值与展望。以及从产业链维度,让RISC-V进入教育流程,上海开放处理器产业创新中心联合十余高校,发布RISC-V研究生选修课开源课件《RISC-V导论:设计与实践》;还有诸如芯原一直在搞RISC-V的“芯原杯”全国嵌入式软件开发大赛等等……

既然本文以CUDA开头,那么最后也以CUDA来做结。因为除了CPU针对AI推理的指令级加速,戴伟民在圆桌环节还提起了基于RISC-V来做专用AI加速器的问题(比如Tenstorrent采用“baby RISC-V”核心的Blackhole芯片),所以圆桌嘉宾们掀起了有关AI处理器未来发展路线的探讨。
杨静(阿里巴巴达摩院RISC-V副总裁)基于此提到NVIDIA作为一家“软件公司”,其CUDA生态壁垒是绝对强项。作为主控CPU之时,“RISC-V当然会有诸如matrix extension扩展支持”;“也有企业去做基于RISC-V更多的架构创新”;“但我们现在需要的,是做CUDA生态移植或做一套更有效的、能够部署到架构中来的好的方式。所以软件能力对RISC-V会非常重要。”
高鹏(算能高级副总裁)则就此补充说,“RISC-V有机会去挑战CUDA生态。基于开放性、可扩展性特点,RISC-V能够为开发者实现无限的创新。”“这样的创新又以RISC-V国际基金会的标准为共识”,“有创新探索,又有共识,那么未来大量面向AI应用的开发者聚集起来形成新的共识,将会有很大的机会去挑战CUDA生态。”
在我们看来,无论是文首提到CUDA生态的主动兼容,还是藉由架构、软件创新来挑战CUDA生态,这套基于“合作”与“创新”的思路的确是贯彻了今年RISC-V中国峰会全程的。值得一提的是,电子工程专辑还特别就RISC-V在HPC、AI领域的应用发展采访了RISC-V国际基金会CEO Andrea Gallo,欢迎关注我们就此话题的后续报道。

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊