一起聊聊Nvidia Blackwell新特性之使用Thread Block Clusters的 GEMM
- 2025-07-19 23:01:03

作者:企鹅火烈鸟🦩
原文链接:https://research.colfax-intl.com/cutlass-tutorial-gemm-with-thread-block-clusters-on-nvidia-blackwell-gpus/
欢迎阅读我们系列文章的第二部分,该系列探讨了 NVIDIA Blackwell 架构上的 GEMM。在第一部分中,我们介绍了 NVIDIA Blackwell GPU 上的一些关键新特性,包括张量内存,并详细说明了如何编写一个简单的 CUTLASS GEMM 内核,该内核使用新的 UMMA 指令(tcgen05.mma)来针对 Blackwell 张量核心。在本篇文章中,我们将解释如何利用线程块集群和 2-SM UMMA 来实现 Blackwell GEMM。更具体地说,我们将按以下顺序涵盖以下方面:
使用张量内存加速器 (TMA) 与线程块集群和多播,将全局内存传输分配到参与的 CTA 中; 使用 Blackwell 2-SM UMMA 与 CTA 对来提高 MMA 的算术强度; 将 TMA 多播和 2-SM UMMA 结合在 GEMM 主循环中,并正确同步这些操作。
与上一篇文章类似,我们将首先深入讨论相关概念,然后通过 CuTe Blackwell 示例(特别是示例 3 和 4)查看如何在 CUTLASS 中实现它们。这两个示例遵循我们呈现概念的顺序——第三个示例使用 TMA 多播和 Blackwell 1-SM UMMA 进行 GEMM,而第四个示例将其扩展到使用 CTA 对的 2-SM UMMA,并引入新的同步原语,包括不同的多播 TMA 原子。
线程块集群
线程块集群是一种结构,允许开发者将物理上接近的 SM(例如,在芯片上)分组。具体而言,集群中的线程块保证被共同调度到位于同一 GPU 处理集群 (GPC) 上的 SM。

此特性首先在 NVIDIA Hopper 架构中引入,为开发者提供了新的层次结构,以促进相邻线程块之间更高级的合作。值得注意的是,集群中的线程块可以访问彼此的共享内存,这种能力称为分布式共享内存。这也使得集群中的线程块能够协作加载数据(例如,通过 TMA 多播),并使用共同可见的 mbarrier 进行同步。我们将在本文后续部分看到这些特性的实际应用。
使用线程块集群
线程块集群是一个启动时参数,就像网格大小或块大小一样。集群大小以 dim3 元组 <cluster.x, cluster.y, cluster.z> 定义。最大支持的可移植集群大小为 8,尽管某些 GPU(如 Hopper H100 和 Blackwell B200)通过可选选项允许大小高达 16 的集群。我们将最小形状 <1,1,1> 的集群称为平凡集群。最后,集群形状必须均匀划分网格大小。
在 CUTLASS 中,我们使用特殊的启动器实用程序 launch_kernel_on_cluster 来启动集群。
// 定义 dimGrid, dimBlock, dimCluster 为 dim3 对象
// 计算 smemBytes
// 定义 kernel_ptr 为内核函数指针
auto params = {dimGrid, dimBlock, dimCluster, smemBytes};
auto status = cutlass::launch_kernel_on_cluster(params, (void const*) kernel_ptr,
... /* 内核参数 */);
在 GEMM 内核中,自然地将集群形状的三个维度映射到问题的三个维度 (M, N, K)(除非使用 Split-K 内核设计,否则 K 维度的集群形状等于 1)。这意味着每个集群中的 CTA 被分配到连续的输出瓦片块,这有利于缓存性能,并且如我们即将看到的,有利于多播。
TMA 多播
TMA 多播加载是一种旨在通过一次性将相同的张量瓦片加载到同一集群中的多个 CTA 来加速数据传输的特性。此特性与线程块集群和 TMA 一起在 Hopper 中引入,我们在之前的博客文章中已对其进行过介绍。
简要回顾一下,TMA 多播将 TMA 加载的数据放置到同一集群中多个 CTA 的 SMEM 中。使用此特性,集群中的一组 CTA 可以协作并同时将数据瓦片加载到各自的共享内存中,从而在多个 CTA 需要加载相同数据的情况下减少全局内存流量。每个 CTA 加载多播数据的一部分到其他参与 CTA 的 SMEM 中。例如,如果参与 CTA 的数量为 4,则每个 CTA 加载四分之一的数据,从而将 TMA 加载的总数据量减少 4 倍。从技术上讲,这种协作部分加载是一种编程范式,并非 TMA 多播特性的内在部分,但在本文中我们将它们视为同义。
CuTe 示例:使用 TMA 多播的 GEMM
现在让我们查看 CuTe Blackwell 示例 3,并了解多播在 GEMM 上下文中的使用方式。多播自然地转化为 GEMM 的瓦片方案,因为操作数 A 和 B 中的每个瓦片用于计算多个输出瓦片。为简单起见,让我们首先考虑形状为 <2,2,1> 的集群(注意实际示例使用形状 <4,4,1>)。每个 CTA 处理大小为 (bM, bN) 的输出瓦片,因此每个集群处理 2×2 块的 4 个输出瓦片,总大小为 (2*bM, 2*bN)。
在每个主循环迭代中,每个 CTA 必须从 A 加载 (bM, bK) 瓦片,并从 B 加载 (bN, bK) 瓦片,瓦片的 M 和 N 偏移由该 CTA 在网格中的行和列确定,K 偏移由迭代确定。如果使用简单的 TMA,每个输出瓦片将加载 2 个瓦片,导致集群加载 8 个瓦片。虽然一些优化如 CTA 光栅化可以确保大多数加载来自 L2,但很难达到 100% 命中率,即使 L2 命中在 MMA 操作的时间尺度上也有显著延迟。TMA 多播允许我们仅加载最小要求的 4 个瓦片,并将它们放置到需要它们的 CTA 的 SMEM 中。更精确地说,每个 CTA 需要与同一行中所有其他 CTA 相同的 A 操作数瓦片,以及与同一列中所有其他 CTA 相同的 B 操作数瓦片。因此,每个 CTA 参与两个 TMA 多播操作——一个用于操作数 A,与同一行中的所有其他 CTA;另一个用于操作数 B,与同一列中的所有其他 CTA。

从概念上讲,TMA 多播相当简单。然而,在实际中,协调多个 CTA 的数据访问可能很棘手。因此,可以说 TMA 多播的关键是适当的同步。从 CTA 的工作流程角度来看,有两个同步点——一个是当所有参与 TMA 完成且数据准备好用于 MMA 时,另一个是当所有参与 MMA 完成且持有数据的缓冲区可以被下一迭代的数据覆盖时。我们将依次讨论这两个点。
同步 TMA 参与者
第一个同步点是等待加载所需操作数的所有 TMA 多播完成。再一次,对于 A,这是同一行中的所有 CTA,对于 B,这是同一列中的所有 CTA(注意这包括 CTA 本身)。因此,我们需要一个屏障,等待所有参与相关 TMA 多播操作的集群 CTA。
为了了解如何实现这一点,让我们查看相关的 PTX。参与信息编码在 cp.async.bulk.tensor (TMA) 的 PTX 中:
// global -> shared::cluster
cp.async.bulk.tensor.dim.dst.src{.load_mode}.completion_mechanism{.multicast}
{.cta_group}{.level::cache_hint}
[dstMem], [tensorMap, tensorCoords],
[mbar]{, im2colInfo}
{, ctaMask} {, cache-policy}
.dst = { .shared::cluster }
.src = { .global }
.dim = { .1d, .2d, .3d, .4d, .5d }
.completion_mechanism = { .mbarrier::complete_tx::bytes }
.cta_group = { .cta_group::1, .cta_group::2 }
.load_mode = { .tile, .tile::gather4, .im2col, .im2col::w, .im2col::w::128 }
.level::cache_hint = { .L2::cache_hint }
.multicast = { .multicast::cluster }
TMA 多播参与通过 ctaMask 指定,这是一个位掩码,第 i 位确定集群索引为 i 的 CTA 是否参与。更精确地说,TMA 操作将加载的数据放置到位掩码指定的所有 CTA 的 SMEM 中,并可选地到达 CTA 的 mbarrier。Blackwell GPU 的最大集群大小为 16,因此我们有一个 16 位位掩码。在我们特定集群形状 4x4x1 的情况下,我们可以使用十六进制表示此掩码来获得(相对)人性化的表达式。例如,集群索引为 0 的 CTA 具有 tma_bitmask_a = 0x1111 和 tma_bitmask_b = 0x000f。

这里每个位对应一个 CTA,多维集群形状通过列优先布局映射到 CTA 的一维排序。(集群中每个 CTA 的一维位置可以通过 PTX 特殊寄存器 %cluster_ctarank 或使用 cute::block_rank_in_cluster() 访问。)我们可以看到列和行参与如何编码在掩码中:例如,在 A 的位掩码中,CTA 0 与 CTA 4、8 和 12 共享行,因此掩码 0b0001000100010001 在位 0、4、8 和 12 上为 1。由 CTA 0 发出的 TMA 多播操作将加载的数据放置到 CTA 0、4、8 和 12 的 SMEM 中,并到达每个的 mbarrier。同一行 CTA 的 A TMA 多播都使用相同的位掩码(顶部行的 0x1111),同一列 CTA 的 B TMA 多播都使用相同的位掩码(最左列的 0x000f)。这允许 CTA 只等待参与其操作数多播加载的 6 个其他 CTA。
现在让我们看看如何在示例中实现此 TMA 多播和同步。首先,复制原子。示例使用 sm90 TMA 原子来处理这种单个 SM 的简单情况。参数与标准 TMA 相同,多播模式下的 CTA 数量附加在其后。请注意,多播模式(给出参与者数量)对于 A(A 为 MxK)选择为 N 模式。
Copy_Atom tma_atom_A = make_tma_atom(
SM90_TMA_LOAD_MULTICAST{}, // TMA load operation with multicast
mA, // Source GMEM tensor
sA_layout, // Destination SMEM layout
select<0,2>(mma_tiler), // MK Tiler for TMA operation
size<2>(cluster_layout_vmnk) // The number of CTAs in the multicasting mode
);
接下来,要启动 TMA 多播,我们需要位掩码。此位掩码可以通过 CUTLASS 的实用函数构建:
int cta_in_cluster_coord_1d = cute::block_rank_in_cluster(); // e.g. 11
auto cta_in_cluster_coord_vmnk = cluster_layout_vmnk.get_flat_coord(
cta_in_cluster_coord_1d);
// e.g. (0,3,2,0)
uint16_t tma_mcast_mask_a = create_tma_multicast_mask<2>(cluster_layout_vmnk,
cta_in_cluster_coord_vmnk);
uint16_t tma_mcast_mask_b = create_tma_multicast_mask<1>(cluster_layout_vmnk,
cta_in_cluster_coord_vmnk);
// printf("%#x\n", tma_mcast_mask_a); => 0x8888
// printf("%#x\n", tma_mcast_mask_b); => 0x0f00
我们需要的 TMA 多播的最终信息集是数据张量。我们可以使用 TMA 分区器获取分区瓦片:
// Project the cluster_layout for tma_A along the N-modes
auto [tAgA, tAsA] = tma_partition(tma_atom_A,
get<2>(cta_in_cluster_coord_vmnk),
make_layout(size<2>(cluster_layout_vmnk)),
group_modes<0,3>(tCsA), group_modes<0,3>(tCgA));
// Project the cluster_layout for tma_B along the M-modes
auto [tBgB, tBsB] = tma_partition(tma_atom_B,
get<1>(cta_in_cluster_coord_vmnk),
make_layout(size<1>(cluster_layout_vmnk)),
group_modes<0,3>(tCsB), group_modes<0,3>(tCgB));
// tAgA: ArithTuple(0,0) o (((_64,_128),_1),4):(((_1@0,_1@1),_0),_64@0)
// tAsA: Sw<3,4,3>_smem_ptr[16b](0xfe2600000400) o ((_8192,_1)):((_1,_0))
// tBgB: ArithTuple(0,0) o (((_64,_256),_1),4):(((_1@0,_1@1),_0),_64@0)
// tBsB: Sw<3,4,3>_smem_ptr[16b](0xfe2600004400) o ((_16384,_1)):((_1,_0))
这里有一个有趣的注意点,即使每个 CTA 负责从 GMEM 加载共享瓦片的一部分,但这里的分区张量显示了整个瓦片。事实上,这些张量看起来与常规 TMA 相同。这是因为关于 TMA 多播切片的信呼吸通过内存地址偏移传输,该偏移存储在 ArithTuple(0,0) 中。但因为此打印输出是在 CTA 0 上产生的,所以偏移为零。我们可以通过查看 CTA 1 的 tAgA 来看到此偏移:
// tAgA: ArithTuple(0,128) o (((_64,_128),_1),4):(((_1@0,_1@1),_0),_64@0)
每个 CTA 接收整个瓦片的相同布局,但不同的内存偏移指示它们复制数据的哪个切片。对于更深入的讨论,我们参考我们之前的 TMA 博客文章。
我们现在拥有启动 TMA 多播和同步所需的所有信息。除了参数中的位掩码外,TMA 启动本身与我们之前介绍的标准 TMA 启动相同:
if (elect_one_warp && elect_one_thr) {
cute::initialize_barrier(shared_storage.tma_barrier, 1);
}
int tma_barrier_phase_bit = 0;
cute::cluster_sync();
int tma_transaction_bytes = sizeof(make_tensor_like(tAsA))
+ sizeof(make_tensor_like(tBsB));
// Main loop
for (int k_tile = 0; k_tile < size<3>(tCgA); ++k_tile) {
if (elect_one_warp && elect_one_thr) {
cute::set_barrier_transaction_bytes(shared_storage.tma_barrier,
tma_transaction_bytes);
copy(tma_atom_A.with(shared_storage.tma_barrier,tma_mcast_mask_a),
tAgA(_,k_tile), tAsA);
copy(tma_atom_B.with(shared_storage.tma_barrier,tma_mcast_mask_b),
tBgB(_,k_tile), tBsB);
}
// Wait for TMA loads to SMEM to complete
cute::wait_barrier(shared_storage.tma_barrier, tma_barrier_phase_bit);
tma_barrier_phase_bit ^= 1;
// ... Execute UMMA operation ...
}
这里需要注意的一个重要事项是 TMA 屏障完成,以及 transaction_bytes 的值。mbarrier 对象有两个内部计数器用于跟踪当前阶段的完成:线程中的待到达计数和字节中的待事务计数 (tx-count)。当两个计数都达到 0 时,阶段完成。这里感兴趣的主要计数是 tx-count,它使用 cute::set_barrier_transaction_bytes 设置为预期 TMA 加载的大小。(作为旁注,此函数内部调用 mbarrier.arrive.expect_tx,它消耗初始化中设置的 1 的到达计数。)在到达时,TMA 复制通过复制的数据量(字节)递减 mbarrier 的 tx-count。我们将其设置为操作数瓦片的总大小,因为在继续 UMMA 之前,我们需要等待所有参与 CTA 加载所有操作数数据。
同步 post-UMMA
本例中的 UMMA 与我们在上一篇文章中看到的相同,因此我们将重点关注屏障同步。UMMA 是一个异步操作,因此我们必须明确等待其完成。在之前的示例中,我们只需等待执行 CTA 完成 MMA,然后继续下一迭代。然而,这里我们还需要确保其他 CTA 在通过多播覆盖 SMEM 之前完成消耗操作数数据。换句话说,每个 CTA 需要等待自己和所有与其他 CTA 共享操作数数据的 CTA 完成其 MMA,然后才能发出下一 TMA 加载。
一个简单的解决方案是简单添加 cute::cluster_sync() 并确保集群中的所有 CTA 完成后再继续。但我们可以做得更好;cluster_sync() 过度,因为对于给定瓦片,并非所有 CTA 都在使用它进行 GEMM。相反,每个 CTA 应仅等待共享其 A 瓦片的 3 个其他 CTA,以及共享其 B 瓦片的 3 个其他 CTA。这种针对性同步将允许集群中的一些 CTA 提前运行并发出 TMA 加载,而其他 CTA 仍在完成其 MMA 操作。
这种子集群级别的同步类似于我们为 TMA 多播看到的。但由于它现在链接到异步张量核心操作的完成,它使用一些 Blackwell 新指令,特别是 tcgen05.commit 指令或其 CUTLASS 包装器 cutlass::arch::umma_arrive_multicast。此指令将之前的异步 tcgen05 操作(如 UMMA)分组,并设置它们在完成时到达集群中某些 CTA 的共享内存空间中的 mbarrier,由位掩码指定。
因此,我们将设置一个类似于 TMA 创建的位掩码同步。这次,我们需要一个掩码,编码哪些其他 CTA 正在使用该 CTA 已加载的瓦片。为了构建此掩码,我们可以使用之前创建的 TMA 位掩码。A 的位掩码告诉我们哪些其他 CTA 正在使用 A 操作数,B 的位掩码类似。因此,我们可以通过取两个掩码的按位 OR 来获取所需的位掩码。例如,对于集群索引 0 的 CTA,我们发现 TMA 位掩码为 tma_bitmask_a = 0x1111 和 tma_bitmask_b = 0x000f。因此 MMA 位掩码为 tma_bitmask_a|tma_bitmask_b = 0x111f。
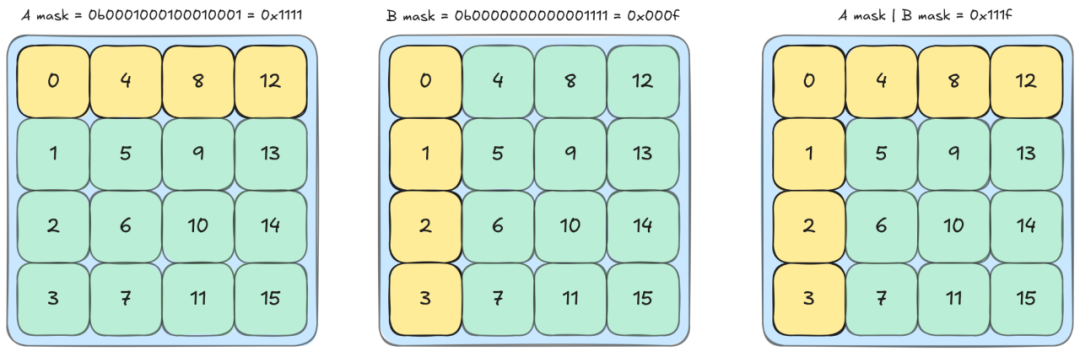
我们在图中可以看到,此位掩码识别与 CTA 0 共享瓦片的 CTA,即同一列或行中的 CTA。
使用此位掩码,我们可以设置 MMA 同步。第一步,mbarrier 创建,与 TMA 情况有一个关键区别——由于没有数据传输,我们依赖到达计数而不是 tx-count。具体而言,屏障计数需要设置为等于参与 MMA 的数量。在本例中,每个 CTA 的屏障需要等待 7 个线程;这计数所有出现在掩码中的 CTA(包括自身)中发出 MMA 的所有线程。更一般地,此数字可以从集群布局中检索,确保避免双重计数自身。
if (elect_one_warp && elect_one_thr) {
int num_mcast_participants = size<1>(cluster_layout_vmnk)
+ size<2>(cluster_layout_vmnk) - 1;
cute::initialize_barrier(shared_storage.mma_barrier, num_mcast_participants);
}
最后,我们可以设置同步。我们将发出 tcgen05.mma 的内循环与 umma_arrive_multicast 分组,并指示它在完成时到达位掩码指定的 CTA 的 mbarrier。
if (elect_one_warp) {
for (int k_block = 0; k_block < size<2>(tCrA); ++k_block) {
gemm(tiled_mma, tCrA(_,_,k_block), tCrB(_,_,k_block), tCtAcc);
tiled_mma.accumulate_ = UMMA::ScaleOut::One;
}
cutlass::arch::umma_arrive_multicast(&shared_storage.mma_barrier,
mma_mcast_mask_c);
}
cute::wait_barrier(shared_storage.mma_barrier, mma_barrier_phase_bit);
mma_barrier_phase_bit ^= 1;
// continue to TMA in next iteration
注意,umma_arrive_multicast 内部选举一个线程到达屏障,因此我们不应像 TMA 设置事务计数那样明确选举线程。使用此针对性屏障,CTA 可以继续执行,而无需等待集群中的所有 CTA——只需那些具有数据依赖的 CTA。它将能够为下一个 k 迭代启动 TMA,即使集群中的一些其他 CTA 仍在计算 MMA。
CuTe 示例:使用 TMA 多播的 Pair-UMMA
接下来,让我们检查示例 4,其中我们遇到 2 SM 情况。从上一篇文章回忆,Blackwell 添加了两个相邻 CTA 在同一集群中联合处理 UMMA 的能力。据我们所知,这种 MMA 变体没有官方名称,因此我们将其称为 2-SM UMMA 或 pair-UMMA。同样,当需要澄清时,我们将使用 1-SM UMMA 或 single-UMMA。
Pair-UMMA 为索引添加了复杂性,因为现在我们需要区分 MMA 坐标和 CTA 坐标。以前,每个 CTA 在每个主循环迭代中计算 (bM, bN, bK) MMA 操作。因此,CTA 自然排列在三维网格中。随着 Pair-UMMA 的引入,现在最好将其视为 (bM, bN, bK) MMA 瓦片的网格,其中单个 MMA 瓦片可能由 1 或 2 个 CTA 的 CTA 组计算。这意味着 CTA 最好被视为位于四维网格上,其中第 0 个“值”模式表示组内 CTA 的索引。请注意,此概念步骤实际上不受 CUDA 语法支持,CUDA 语法仅使用三维网格形状,因此必须手动进行一些 CTA 索引的算术。
在本节中,我们将首先深入探讨考虑 CTA 对时的两个索引方案。然后我们将通过示例讨论 pair-UMMA 如何改变索引和分区。最后,一旦我们知道每个 CTA 上需要哪些数据,我们将检查 CTA 对如何改变我们使用 TMA 的方式。
用于 CTA 对的线程块集群
CTA 对必须位于单个集群中,集群内的 CTA 使用集群中的 CTA ID 排序成对。具体而言,索引的第 0 位不同的 CTA(例如 0 和 1、2 和 3 等)被视为对。在对中,索引为偶数的 CTA 称为偶 CTA,索引为奇数的 CTA 称为奇 CTA。
现在考虑集群形状 <4,4,1>,它有 8 对。由于这是 CuTe,此形状在索引中是列优先的;因此配对在大小至少为 2 的最左模式上。对于 <4,4,1>,这意味着第 0 模式确定配对。请注意,配对模式的选则可能受特定张量核心操作的限制;例如,pair-UMMA 要求配对在 M 模式上。
让我们回顾我们在上一篇文章中简要介绍的 cluster_shape_vmnk。
Layout cluster_layout_vmnk = tiled_divide(make_layout(cluster_shape),
make_tile(typename TiledMMA::AtomThrID{}));
我们看到,当使用 single-UMMA 时,AtomThrID{} 的值为 1,cluster_layout_vmnk 简化为 <1,cluster.x,cluster.y,cluster.z>。但现在我们有 pair-UMMA 原子,因此 AtomThrID{} 为 2。因此,在这种情况下,tiled_divide 将沿集群形状的第 0 模式以 (2) 的瓦片平铺,创建 CTA 集群的 rank-4 布局。第 0 个“值”模式将确定对内的 ID,其他三个模式形成集群中 CTA 对的布局。例如,对于集群形状 <4,4,1>:
auto cluster_shape = make_shape(Int<4>{}, Int<4>{}, Int<1>{});
Layout cluster_layout_vmnk = tiled_divide(make_layout(cluster_shape),
make_tile(typename TiledMMA::AtomThrID{}));
print(cluster_layout_vmnk); // ((_2),_2,_4,_1)
我们可以将其读取为排列在形状 (2,4,1) 中的 8 个 CTA 对。然后,此集群布局用于计算 mma_coord_vmnk。
Layout cluster_layout_vmnk = tiled_divide(make_layout(cluster_shape),
make_tile(typename TiledMMA::AtomThrID{}));
auto mma_coord_vmnk = make_coord(blockIdx.x % size<0>(cluster_layout_vmnk),
blockIdx.x / size<0>(cluster_layout_vmnk),
blockIdx.y,
_);
mma_coord_vmnk 是一种复合坐标系统;第 0 模式是单个 MMA 内对等 CTA 坐标,而模式 1 到 3 是 MMA 的全局坐标。这些后三个模式构成 MMA 坐标,这些坐标用于索引 MMA 瓦片。Blackwell 架构的 MMA 是对本地化的,而不是 Hopper 架构中的 CTA 本地化。
Pair-UMMA
在 pair-UMMA 中,对中的 CTA 协作处理相同的 MMA 瓦片。对中的每个 CTA 加载每个 MMA 操作数瓦片的一半,并在 TMEM 中持有累加器的一半。例如,如果 MMA 是 256x256x16,则每个 CTA 从 A 和 B 加载 128×16 切片,并在 TMEM 中持有 128×256 累加器矩阵。

我们在这里看到没有重叠数据加载。因此,在算术强度方面,这真正像一个 256×256 MMA;与两个 CTA 执行两个单独的 128×256 MMA 相比,256×256 MMA 执行相同数量的 FLOPs,但传输一半的操作数数据。
Pair-UMMA 使用带有限定符 cta_group::2 的 tcgen05.mma 指令从 PTX 发出。M 的支持大小为 128 和 256,累加器总是沿 M 方向在两个 CTA 之间拆分,这对选择集群形状有一些影响。请参阅 PTX 指南以获取有关数据布局的更多信息。
在 CUTLASS 中,Pair-UMMA 的构造函数与单个 CTA MMA 相同:
TiledMMA tiled_mma = make_tiled_mma(SM100_MMA_F16BF16_2x1SM_SS<TypeA, TypeB, TypeC,
256, 256,
UMMA::Major::K,
UMMA::Major::K>{});
然而,在底层,single-UMMA 和 pair-UMMA 之间的 TiledMMA 对象有许多信息差异。打印上述 tiled_mma 给出:
TiledMMA
ThrLayoutVMNK: (_2,_1,_1,_1):(_1,_0,_0,_0)
PermutationMNK: (_,_,_)
MMA_Atom
ThrID: _2:_1
Shape_MNK: (_256,_256,_16)
LayoutA_TV: (_2,(_128,_16)):(_128,(_1,_256))
LayoutB_TV: (_2,(_128,_16)):(_128,(_1,_256))
LayoutC_TV: (_2,(_128,_256)):(_128,(_1,_256))
如上一篇文章所述,线程索引已被重新用于作为 CTA 对的索引。由于这是 pair-UMMA,ThrID 为 2,所有布局相应地在第 0 模式中具有大小 2。
接下来讨论分区。每个 CTA 组与全局内存张量的 MMA 瓦片关联,我们可以使用 local_tile 如常提取:
auto mma_coord = select<1,2,3>(mma_coord_vmnk); // extract MMA coordinates
Tensor gA = local_tile(mA, mma_tiler, mma_coord, Step<_1, X,_1>{});
Tensor gB = local_tile(mB, mma_tiler, mma_coord, Step< X,_1,_1>{});
Tensor gC = local_tile(mC, mma_tiler, mma_coord, Step<_1,_1, X>{});
Tensor gD = local_tile(mD, mma_tiler, mma_coord, Step<_1,_1, X>{});
// gA: (MmaTile_M, MmaTile_K, Tiles_K), e.g. (_256, _64, 4)
// gB: (MmaTile_N, MmaTile_K, Tiles_K), e.g. (_256, _64, 4)
// gC, gD: (MmaTile_M, MmaTile_N) = (_256, _256)
然后,这些 MMA 瓦片使用 ThrMMA::partition_[A|B|C] 方法在组内的 CTA 之间分区,以获取 CTA 本地操作数和累加器瓦片。
auto mma_v = get<0>(mma_coord_vmnk); // extract peer CTA coordinate
ThrMMA cta_mma = tiled_mma.get_slice(mma_v);
Tensor tCgA = cta_mma.partition_A(gA);
Tensor tCgB = cta_mma.partition_B(gB);
Tensor tCgC = cta_mma.partition_C(gC);
Tensor tCgD = cta_mma.partition_C(gD);
// tCgA: (MmaA, NumMma_M, NumMma_K, Tiles_K), e.g. ((_128,_16),_1,_4,4)
// tCgB: (MmaB, NumMma_N, NumMma_K, Tiles_K), e.g. ((_128,_16),_1,_4,4)
// tCgC, tCgD: (MmaC, NumMma_M, NumMma_N), e.g. ((_128,_256),_1,_1)
一种有用的思考方式是早期观察到 CTA 坐标已取代线程坐标。在 Hopper 和更早的 GEMM 内核中加载操作数矩阵时,CTA 本地瓦片由线程 ID 切片以提取线程本地分区。在 Blackwell 上,每个 MMA 本地瓦片由对等 CTA ID 切片以获取 CTA 本地分区。本示例中的代码是通用的,也适用于 single-UMMA,在这种情况下,所有 V 维度的大小均为 1,每个 MMA 瓦片包含单个 CTA 分区。
作为最后注意,pair-UMMA 必须从我们选举为领导 CTA 的 CTA 中的一个线程启动;在 CUTLASS 中,我们总是选择偶 CTA 作为领导。
int cta_rank = int(cute::block_rank_in_cluster());
auto cta_in_cluster_coord_vmnk = cluster_layout_vmnk.get_flat_coord(cta_rank);
auto elect_one_cta = get<0>(cta_in_cluster_coord_vmnk) == Int<0>{};
if (elect_one_cta) {
// Issue pair-UMMA from single thread
}
TMA 多播和 Pair-UMMA 主循环
现在我们有了启用 pair-UMMA 的 tiled_mma 对象,让我们查看示例 4 中呈现的实现。主要内核工作流程如下:
// Compute the bitmasks for TMA and pair-UMMA
uint16_t tma_mcast_mask_a =
create_tma_multicast_mask<2>(cluster_layout_vmnk,cta_in_cluster_coord_vmnk);
uint16_t tma_mcast_mask_b =
create_tma_multicast_mask<1>(cluster_layout_vmnk,cta_in_cluster_coord_vmnk);
uint16_t mma_mcast_mask_a =
create_tma_multicast_mask<0,2>(cluster_layout_vmnk,cta_in_cluster_coord_vmnk);
uint16_t mma_mcast_mask_b =
create_tma_multicast_mask<0,1>(cluster_layout_vmnk,cta_in_cluster_coord_vmnk);
uint16_t mma_mcast_mask_c = mma_mcast_mask_a | mma_mcast_mask_b;
// Transaction count is the entire MMA
int tma_transaction_bytes = size<0>(cluster_layout_vmnk)
* sizeof(make_tensor_like(tAsA))
+ size<0>(cluster_layout_vmnk)
* sizeof(make_tensor_like(tBsB));
// Initialize barriers
if (elect_one_warp && elect_one_thr) {
int num_mcast_participants = size<1>(cluster_layout_vmnk)
+ size<2>(cluster_layout_vmnk) - 1;
cute::initialize_barrier(shared_storage.mma_barrier, num_mcast_participants);
cute::initialize_barrier(shared_storage.tma_barrier, 1);
}
int mma_barrier_phase_bit = 0;
int tma_barrier_phase_bit = 0;
cute::cluster_sync();
tiled_mma.accumulate_ = UMMA::ScaleOut::Zero;
for (int k_tile = 0; k_tile < size<3>(tCgA); ++k_tile)
{
if (elect_one_warp && elect_one_thr) {
// Only the leader CTA waits for TMA transactions
if (elect_one_cta) {
cute::set_barrier_transaction_bytes(shared_storage.tma_barrier,
tma_transaction_bytes);
}
copy(tma_atom_A.with(shared_storage.tma_barrier,tma_mcast_mask_a),
tAgA(_,k_tile), tAsA);
copy(tma_atom_B.with(shared_storage.tma_barrier,tma_mcast_mask_b),
tBgB(_,k_tile), tBsB);
}
if (elect_one_cta) {
// Only the leader CTA waits for the TMA
cute::wait_barrier(shared_storage.tma_barrier, tma_barrier_phase_bit);
tma_barrier_phase_bit ^= 1;
if (elect_one_warp) {
for (int k_block = 0; k_block < size<2>(tCrA); ++k_block) {
gemm(tiled_mma, tCrA(_,_,k_block), tCrB(_,_,k_block), tCtAcc);
tiled_mma.accumulate_ = UMMA::ScaleOut::One;
}
// Only the leader arrives for CTA
cutlass::arch::umma_arrive_multicast_2x1SM(&shared_storage.mma_barrier,
mma_mcast_mask_c);
}
}
// All CTAs wait
cute::wait_barrier(shared_storage.mma_barrier, mma_barrier_phase_bit);
mma_barrier_phase_bit ^= 1;
}
在本节的其余部分,我们将深入检查此示例的不同组件。
构建位掩码
首先,我们将涵盖 TMA 和 MMA 位掩码。请回忆位掩码指示 TMA 和 MMA 的数据依赖,因此让我们从理解它如何从单个 CTA 情况改变开始。在 2SM 情况下,每个 CTA 负责 MMA 瓦片的不重叠一半;偶 CTA 不需要奇 CTA 的数据,反之亦然。因此 TMA 多播只需多播到具有相同奇偶性的 CTA。另一方面,MMA 使用整个 MMA 瓦片,因此它需要两个 CTA 奇偶性的数据。这反映在位掩码中。
例如,在集群形状为 <4,4,1> 的情况下(导致形状 <2, 2, 4, 1> 的四维集群),CTA 0 具有以下位掩码:
tma_mcast_mask_a: 0x1111
tma_mcast_mask_b: 0x0005
mma_mcast_mask_c: 0x333f
图 6 显示了此 pair-UMMA 示例的位掩码到 CTA 映射。

对于 TMA 多播掩码,对于 CTA 0,只有行或列中的偶 CTA 设置为 1,因为奇 CTA 是数据独立的。但对于 MMA,两个一半都设置为 1,因为 MMA 使用两个一半。
为了构建这些掩码,我们可以再次使用第 2-10 行中显示的 CUTLASS 实用函数。构建与 1 SM 情况不同,因为 CTA 的 MMA 位掩码不再是其 TMA 位掩码的按位 OR,而是其 TMA 位掩码与其对等 MMA 位掩码的按位 OR。一般而言,create_tma_multicast_mask<Modes...>(cluster_layout_vmnk, cta_in_cluster_coord_vmnk) 生成一个位掩码,由所有 CTA 组成,这些 CTA 仅在给定集群布局模式中与指定 CTA 不同。因此 create_tma_multicast_mask<2> 创建参与此 A 瓦片 TMA 加载的 CTA 的掩码(可能在 N 模式中与此 CTA 不同),而 create_tma_multicast_mask<0,2> 创建参与使用此 A 瓦片的 MMA 的 CTA 的掩码(可能在 V 和 N 模式中与此 CTA 不同)。MMA 的最终掩码包含参与使用此 A 瓦片或 B 瓦片的 MMA 的所有 CTA,即可能在 V 和 N 模式或 V 和 M 模式中不同的 CTA。
同步 pair-UMMA
现在让我们查看 UMMA 的同步。因为启动来自偶 CTA,因此 UMMA 的到达指令也必须来自偶 CTA。因此,在创建 MMA 屏障时,mma 屏障的参与者数量是 MMA 的数量而不是 CTA 的数量。我们在第 20-21 行看到这一点。在 cluster_shape_vmnk 中,M 模式的大小为 2,N 模式的大小为 4。因此参与者(到达计数)为 5,尽管事实上涉及 10 个 CTA。
pair-UMMA 的到达指令使用特殊的 CUTLASS 函数 umma_arrive_multicast_2x1SM 发出(见第 55-56 行)。这是因为带有 cta_group::1 和 cta_group::2 的 tcgen05.commit 调用在单独的管道中处理。Pair-UMMA 使用 cta_group::2 限定符启动,因此我们需要指示 tcgen05.commit 查找 cta_group::2。
如果对于给定 MMA 瓦片只有 5 个领导 CTA 将到达此屏障,为什么我们传入大小为 10 的位掩码,也包含非领导 CTA?答案是位掩码确定发出 CTA 到达哪些 CTA 的屏障。(记住,由于这些 CTA 在集群中,它们可以访问彼此共享内存中的 mbarrier。)尽管只有 5 个领导 CTA 发出 MMA 指令,但非领导 CTA 也必须等待 MMA 完成,然后才能发出下一 TMA 复制并使操作数无效。我们可以看到所有 CTA 在第 60-61 行等待。
用于 2SM 的 TMA 多播同步
现在是 TMA 多播同步。在第 38-41 行,TMA 使用位掩码启动,该位掩码将多播限制到具有相同奇偶性的 CTA,因为每个 CTA 只负责 MMA 瓦片的一半。此位掩码也意味着通常这些 TMA 只到达具有相同奇偶性的 CTA。然而,TMA 的 wait_barrier(第 46 行)仅从偶 CTA 调用,它必须等待整个 MMA 瓦片。因此奇 CTA 以某种方式需要到达偶 CTA 的 mbarrier,尽管占用完全不相交的 TMA 位掩码。
CUTLASS 以一种启发性的方式解决此问题。首先,sm100 为 TMA 复制指令引入了 cta_group 限定符。将此设置为 cta_group::2 允许 TMA 复制到达执行 CTA 或其对等 CTA 的 mbarrier。其次,这里使用的 cute::copy 版本使用以下修改 mbarrier 地址:
uint32_t smem_int_mbar = cast_smem_ptr_to_uint(mbar_ptr) & Sm100MmaPeerBitMask;
其中 Sm100MmaPeerBitMask 为 0xFEFFFFFF。换句话说,CTA 可以通过取其自身 mbarrier 地址并将第 24 位设置为 0 来找到其领导 CTA 的 mbarrier 地址。这有效,因为集群中所有 CTA 的 SMEM 被视为单个统一地址空间(对应 PTX 的“共享状态空间”),集群中的 CTA ID 占用地址的高位。特别是,地址的第 24 位必须对应 CTA ID 的第 0 位,这是 CTA 在其对中的索引。请注意,使用 cute::copy 进行此 TMA 复制要求集群中的所有 CTA 具有相同的共享存储布局,并要求我们采用 CUTLASS 的惯例,选择偶 CTA 作为领导。
可以使用特殊的函数 make_tma_atom_[A|B]_sm100() 创建对专用的复制原子,该函数与 sm90 接口略有不同,并要求更多关于 UMMA 本身的细节作为参数。以下是示例 4 的原子。
Copy_Atom tma_atom_A = make_tma_atom_A_sm100(
SM100_TMA_2SM_LOAD_MULTICAST{},
mA, // Source GMEM tensor
sA_layout, // Destination SMEM layout
mma_tiler, // MMA tile shape, e.g. (_256, _256, _64)
tiled_mma,
cluster_layout_vmnk);
请注意,与早期的 1SM 情况不同,我们在这里不手动指定多播维度。相反,多播维度由 make_tma_atom_[A|B]_sm100 函数适当选择。这是因为多播维度由 MMA 原子的限制确定,该原子总是沿 M 维度拆分累加器。打印此 TMA 原子,我们可以看到前线程模式再次被用作对等 CTA 模式。
tma_atom_A: Copy_Atom
ThrID: _2:_1
ValLayoutSrc: (_2,_8192):(_8192,_1)
ValLayoutDst: (_2,_8192):(_8192,_1)
ValLayoutRef: (_2,_8192):(_8192,_1)
ValueType: 16b
这表示两个数据独立的 128x16x4 加载(回忆我们每个 SMEM 瓦片有 4 个主循环迭代)。
结论
在本博客文章中,我们通过 CuTe Blackwell 示例 3 和 4 检查了 NVIDIA Blackwell 架构的线程块集群的高级用法。特别是,我们查看了 TMA 多播和 2-SM UMMA(即 pair-UMMA)。对于两个特性,我们首先深入探讨了如 PTX、索引逻辑和位掩码等细微细节。然后我们查看了 CUTLASS 实现,其中我们发现复杂的索引逻辑被 CuTe 布局和实用函数抽象掉。
到目前为止,我们仅涵盖了使用半精度数据类型的标准 GEMM。然而,Blackwell 架构添加了对低精度 GEMM 的额外支持,包括块缩放。我们将在本系列的下一篇文章和最终文章中转向此主题。
-- 完 --
机智流推荐阅读:
1. 突破传统交互!滑铁卢大学研发 NeuralOS,让神经网络能靠“画”模拟操作系统界面
2. 发个福利,可以免费领WAIC2025(世界人工智能大会·上海)单日门票
3. 刚刚,ICML 2025 杰出论文揭晓!万中选八,AI安全的头等大事竟然是...打工人的饭碗?
4. ICML 2025 强化学习 RL 方向Oral论文盘点
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群
 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊