


HF 论文周报 | AI 内存 OS 登顶!英伟达发布长视频 RL 框架,LoRA 迎来新架构
- 2025-07-12 17:51:31
🚀 本周热门看点:专为 AI 系统设计的内存操作系统 MemOS 霸榜;英伟达、MIT 联手推出 LongVILA-R1,将强化学习扩展到长视频推理;SingLoRA 仅用单个矩阵实现低秩适配,参数减半性能反超;T-LoRA 解决单图定制过拟合问题;更有关于“MLM 是否已死”的大规模研究。Hugging Face Paper 一周盘点(按投票数倒序)!精彩不容错过!
(1) 🚀 为AI打造专属操作系统:MemOS(104 票)
论文原始英文标题:
MemOS: A Memory OS for AI System
论文链接:
https://huggingface.co/papers/2507.03724
简要介绍:
由 MemTensor(上海)、上海交通大学、中国人民大学等机构提出了MemOS,一个专为AI系统设计的内存操作系统。该工作旨在解决大模型在长上下文推理、持续个性化和知识一致性方面的挑战,通过将内存视为一种可管理的系统资源,统一了不同类型内存(明文、激活、参数)的表示、调度和演化,为实现持续学习和个性化建模奠定了基础。
核心图片:
(2) 🔥 将强化学习扩展至长视频:LongVILA-R1(97 票)
论文原始英文标题:
Scaling RL to Long Videos
论文链接:
https://huggingface.co/papers/2507.07966
简要介绍:
由 NVIDIA、MIT、香港大学和加州大学伯克利分校等机构提出了LongVILA-R1,一个利用强化学习将视觉语言模型(VLM)的推理能力扩展到长视频的端到端框架。该工作通过构建大规模长视频推理数据集、设计两阶段训练流程(CoT-SFT+RL)以及开发高效的长视频RL训练基础设施(MR-SP),成功解决了长视频推理的独特挑战,在多个基准上取得了领先性能,甚至媲美Gemini-1.5-Pro。
核心图片:
(3) 🚀 单矩阵LoRA:更稳定、更高效的SingLoRA(85 票)
论文原始英文标题:
SingLoRA: Low Rank Adaptation Using a Single Matrix
论文链接:
https://huggingface.co/papers/2507.05566
简要介绍:
由以色列理工学院等机构提出了SingLoRA,一种创新的低秩自适应微调方法。传统LoRA使用两个矩阵的乘积进行更新,常因尺度差异导致训练不稳定。SingLoRA巧妙地使用单个低秩矩阵与其转置的乘积(AAᵀ)来更新权重,从根本上消除了矩阵间的尺度冲突,确保了优化过程的稳定性,同时将参数数量减少了约一半。实验表明,SingLoRA在常识推理和图像生成任务上均超越了LoRA和LoRA+。
核心图片: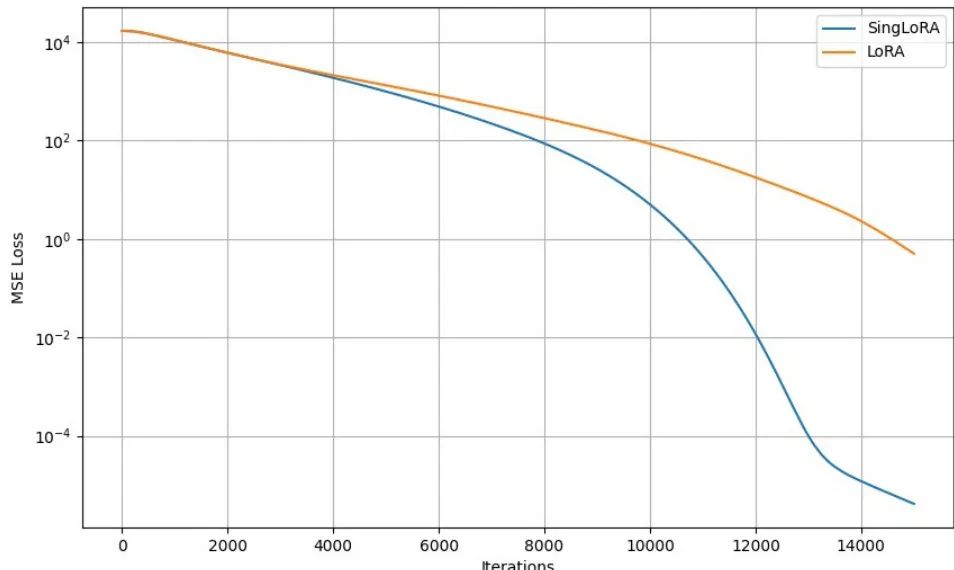
(4) 🔥 T-LoRA:单图定制扩散模型,告别过拟合(83 票)
论文原始英文标题:
T-LoRA: Single Image Diffusion Model Customization Without Overfitting
论文链接:
https://huggingface.co/papers/2507.05964
简要介绍:
由AIRI、HSE University等机构提出了T-LoRA,一个专为解决单图像扩散模型微调中过拟合问题的框架。研究发现,过拟合主要发生在高(噪声)扩散时间步。T-LoRA通过引入时间步依赖的动态微调策略(对高时间步使用更低秩的更新)和正交初始化技术,有效平衡了概念保真度和文本对齐度,在资源有限的单图定制场景下,显著优于标准LoRA。
核心图片:
(5) 🤔 我们还应该用MLM预训练编码器吗?(72 票)
论文原始英文标题:
Should We Still Pretrain Encoders with Masked Language Modeling?
论文链接:
https://huggingface.co/papers/2507.00994
简要介绍:
由Artefact Research Center、CentraleSupélec、Fudan University等机构进行了一项大规模的对照研究,探讨了掩码语言建模(MLM)与因果语言建模(CLM)在预训练编码器中的优劣。通过训练38个模型并进行超过15000次评估,研究发现:虽然MLM在各类文本表示任务上总体表现更优,但CLM训练的模型数据效率更高、微调更稳定。研究进一步证明,采用“先CLM后MLM”的两阶段训练策略,可以在固定的计算预算下实现最佳性能。
核心图片:
(6) 🚀 4KAgent:AI智能体,万物皆可超分至4K(68 票)
论文原始英文标题:
4KAgent: Agentic Any Image to 4K Super-Resolution
论文链接:
https://huggingface.co/papers/2507.07105
简要介绍:
由德州农工大学、斯坦福大学、Snap等机构提出了4KAgent,一个统一的智能体超分辨率通用系统,旨在将任何图像(无论其类型、退化程度或领域)普遍升级到4K分辨率。4KAgent包含三个核心组件:分析图像并制定修复计划的感知智能体、执行计划的修复智能体,以及一个专门的面部修复流程。该系统在11个任务类别、26个基准上刷新了SOTA,展示了其在自然图像、人像、AIGC内容乃至遥感、病理和医学成像等科学领域的卓越性能。
核心图片:
(7) 🔥 潜思默想:一份关于隐式推理的全面综述(68 票)
论文原始英文标题:
A Survey on Latent Reasoning
论文链接:
https://huggingface.co/papers/2507.06203
简要介绍:
来自UCSC、复旦大学、南京大学、北京大学等众多机构的学者联合发布了一篇关于隐式推理(Latent Reasoning)的全面综述。与明确生成文本步骤的思维链(CoT)不同,隐式推理在模型的连续隐藏状态中执行多步推理,摆脱了语言的束缚。这篇综述系统地梳理了隐式推理的各种方法,包括基于激活的循环、隐藏状态传播以及能够压缩显式推理轨迹的微调策略,并探讨了无限深度推理等前沿范式,为LLM认知的前沿研究指明了方向。
核心图片:
(8) 🚀 Agent KB:让智能体跨域学习,举一反三(64 票)
论文原始英文标题:
Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving
论文链接:
https://huggingface.co/papers/2507.06229
简要介绍:
由耶鲁大学、OPPO、华盛顿大学麦迪逊分校等机构提出了AGENT KB,一个分层的经验框架,通过创新的“推理-检索-精炼”流程,使智能体能够解决复杂问题。该框架创建了一个共享知识库,捕获高层问题解决策略和底层执行经验,解决了智能体无法从彼此经验中学习的难题,实现了跨智能体框架的知识迁移。在GAIA和SWE-bench等基准测试中,AGENT KB显著提升了模型的成功率和代码修复率。
核心图片: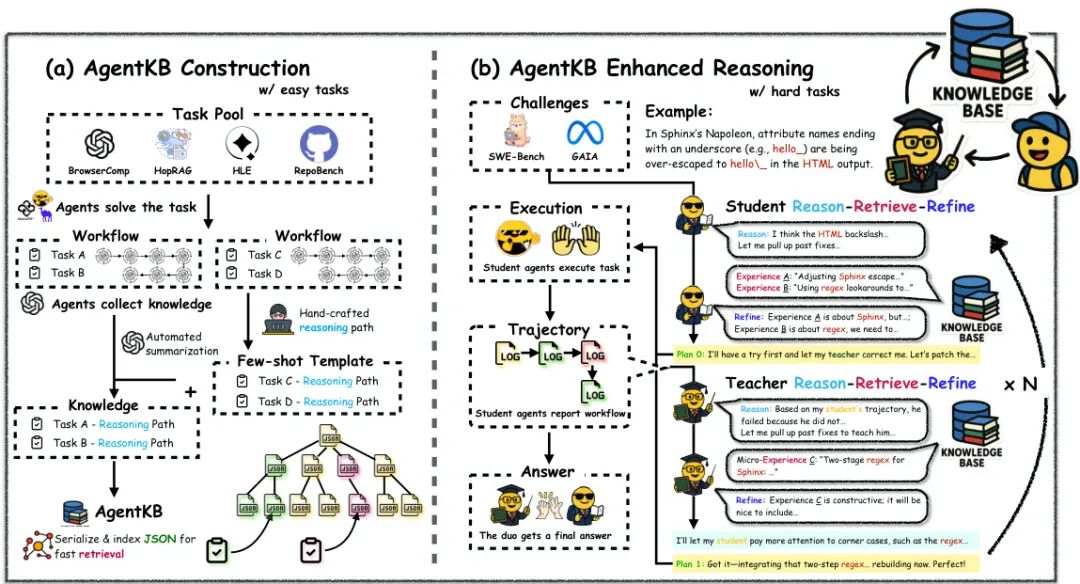
(9) 🔥 Skywork-R1V3:RL激活VLM推理能力,媲美闭源模型(54 票)
论文原始英文标题:
Skywork-R1V3 Technical Report
论文链接:
https://huggingface.co/papers/2507.06167
简要介绍:
由昆仑万维Skywork AI发布了其先进的开源视觉语言模型Skywork-R1V3的技术报告。该模型的核心创新在于,通过一个精心设计的强化学习(RL)后训练框架,无需额外的持续预训练,就能有效地将纯文本LLM的推理能力迁移到视觉任务中。模型在MMMU基准上取得了76.0%的SOTA成绩,达到了入门级人类专家水平。报告还揭示了连接器模块在跨模态对齐中的关键作用,并引入了“关键推理令牌熵”作为衡量推理能力的新指标。
(10) 🚀 OmniPart:像搭乐高一样生成可控的3D模型(49 票)
论文原始英文标题:
OmniPart: Part-Aware 3D Generation with Semantic Decoupling and Structural Cohesion
论文链接:
https://huggingface.co/papers/2507.06165
简要介绍:
由香港大学、哈尔滨工业大学、VAST和浙江大学等机构提出了OmniPart,一个新颖的、部件感知的3D对象生成框架。它将复杂的生成任务分解为两个协同阶段:首先,一个自回归结构规划模块根据用户提供的2D部件掩码生成可控的3D部件边界框序列;然后,一个空间条件的流模型同时、一致地生成所有3D部件。这种方法实现了部件间的高度解耦和整体结构的内聚,支持用户自定义部件粒度,为生成可解释、可编辑的3D内容铺平了道路。
核心图片:
(11) 🔥 MIRIX:多智能体记忆系统,让LLM真正拥有记忆(48 票)
论文原始英文标题:
MIRIX: Multi-Agent Memory System for LLM-Based Agents
论文链接:
https://huggingface.co/papers/2507.07957
简要介绍:
由MIRIX AI提出了MIRIX,一个模块化的多智能体记忆系统,旨在解决当前AI智能体记忆能力有限的核心挑战。MIRIX创新地设计了六种精心结构的记忆类型(核心、情景、语义、程序、资源和知识库),并由一个多智能体框架动态协调。它超越了纯文本,支持丰富的视觉和多模态体验,使智能体能够长期、准确地保留和检索用户数据。在极具挑战性的多模态基准ScreenshotVQA上,MIRIX的准确率比RAG基线高35%,存储需求减少99.9%。
核心图片:
(12) 🚀 迈向零样本:百万级数据驱动的运动生成(45 票)
论文原始英文标题:
Go to Zero: Towards Zero-shot Motion Generation with Million-scale Data
论文链接:
https://huggingface.co/papers/2507.07095
简要介绍:
由上海交通大学、香港中文大学(深圳)、复旦大学、香港科技大学和上海人工智能实验室等机构提出了Go to Zero,旨在将文本到运动生成推向零样本时代。为此,团队构建了迄今为止最大的运动数据集MotionMillion(超过200万个高质量序列),并提出了一个全面的零样本评估基准MotionMillionEval。基于此,他们将模型扩展到7B参数,并验证了其在域外和复杂组合运动上的强大泛化能力,标志着向零样本人类运动生成迈出了重要一步。
(13) 🔥 如何训练你的LLM网页智能体:一份统计诊断报告(44 票)
论文原始英文标题:
How to Train Your LLM Web Agent: A Statistical Diagnosis
论文链接:
https://huggingface.co/papers/2507.04103
简要介绍:
由ServiceNow Research、蒙特利尔大学等机构进行了一项关于LLM网页智能体训练中计算资源分配的统计学研究。研究发现,将SFT与在线RL相结合的混合策略在WorkArena和MiniWob++上始终优于单一方法。更重要的是,这种策略仅需纯SFT峰值性能55%的计算量,就能达到同等效果,有效推动了计算-性能的帕累托前沿,并且是唯一能够缩小与闭源模型差距的策略。这份报告为开源社区训练高效、可复现的网页智能体提供了宝贵的指导。
核心图片:
(14) 🚀 StreamVLN:快慢结合,实现流式视觉语言导航(40 票)
论文原始英文标题:
StreamVLN: Streaming Vision-and-Language Navigation via SlowFast Context Modeling
论文链接:
https://huggingface.co/papers/2507.05240
简要介绍:
由上海人工智能实验室、香港大学、浙江大学和上海交通大学等机构提出了StreamVLN,一个新颖的流式视觉语言导航(VLN)框架。该框架采用创新的“快慢”混合上下文建模策略来处理连续的视觉流输入。其中,“快流式”对话上下文通过滑动窗口实现响应迅速的动作生成,“慢更新”记忆上下文则通过3D感知的令牌修剪策略压缩历史视觉状态。这种设计使得模型在处理长视频流时能保持有界的上下文大小和稳定的低延迟,在VLN-CE基准上取得了SOTA性能。
核心图片:
(15) 🔥 PAPO:感知-策略联合优化,提升多模态推理(39 票)
论文原始英文标题:
Perception-Aware Policy Optimization for Multimodal Reasoning
论文链接:
https://huggingface.co/papers/2507.06448
简要介绍:
由伊利诺伊大学厄巴纳-香槟分校和阿里巴巴集团等机构提出了PAPO,一个新颖的感知-策略联合优化框架,旨在解决多模态推理中常见的视觉感知错误。研究发现,现有RLVR(带可验证奖励的强化学习)方法在多模态任务中表现不佳,67%的错误源于感知。PAPO通过在GRPO目标中引入一个隐式感知损失(KL散度项),激励模型在推理的同时学习感知,且完全依赖内部监督信号。实验证明,PAPO在多模态基准上平均提升4.4%,在视觉依赖性高的任务上提升近8.0%。
核心图片:
(16) 🚀 CriticLean:让“批判家”指导RL,攻克数学形式化(38 票)
论文原始英文标题:
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
论文链接:
https://huggingface.co/papers/2507.06181
简要介绍:
由字节跳动Seed和南京大学等机构提出了CriticLean,一个新颖的、由“批判家”指导的强化学习框架,用于解决数学自动形式化(将自然语言数学问题转为可执行的Lean 4代码)的挑战。该工作将评估语义正确性的“批判家”角色从被动验证者提升为主动学习组件。团队训练了CriticLeanGPT来严格评估形式化的语义保真度,并构建了CriticLeanBench基准来衡量其性能。基于此框架,他们还构建了一个包含超过28.5万个问题的高质量数据集FineLeanCorpus。
核心图片: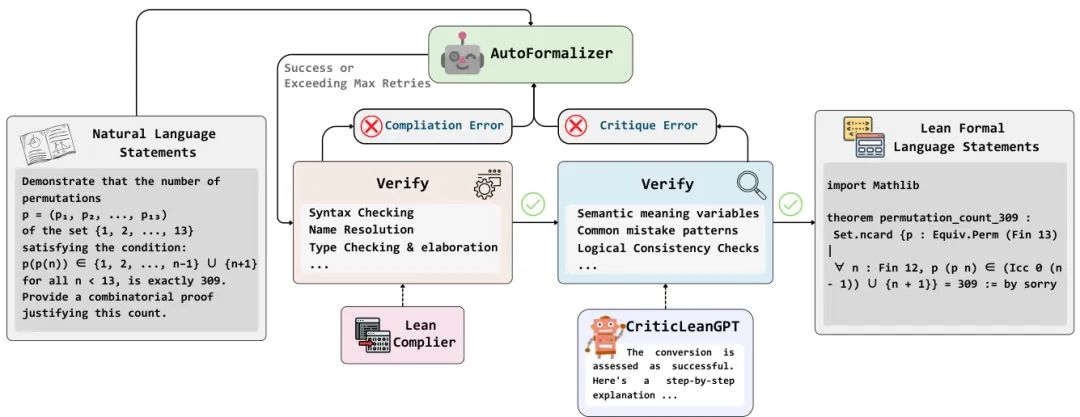
(17) 🔥 4DSloMo:用普通相机捕捉高速动态场景的4D慢动作(37 票)
论文原始英文标题:
4DSloMo: 4D Reconstruction for High Speed Scene with Asynchronous Capture
论文链接:
https://huggingface.co/papers/2507.05163
简要介绍:
由上海人工智能实验室、香港中文大学、香港大学和NVIDIA等机构提出了4DSloMo,一个仅使用低帧率相机实现高速4D捕捉的系统。该方法通过创新的异步捕捉方案(错开相机启动时间)将等效帧率提升至100-200 FPS。针对异步捕捉导致的稀疏视角问题,团队进一步训练了一个基于视频扩散的伪影修复模型,以提升重建质量、保持时间一致性。实验证明,该方法显著增强了高速4D重建效果。
核心图片: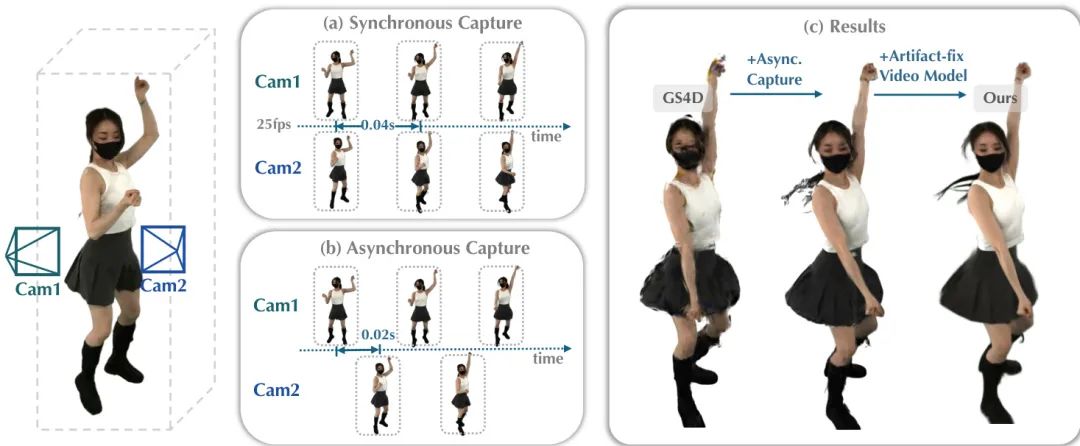
(18) 🚀 TreeBench & TreeVGR:可追溯证据增强视觉推理(37 票)
论文原始英文标题:
Traceable Evidence Enhanced Visual Grounded Reasoning: Evaluation and Methodology
论文链接:
https://huggingface.co/papers/2507.07999
简要介绍:
由中科院自动化所、中国科学院大学和字节跳动等机构提出了TreeBench,一个旨在全面评估LMM“用图像思考”能力的诊断性基准。TreeBench围绕三个核心原则构建:对复杂场景中细微目标的专注视觉感知、通过边界框评估的可追溯证据、以及测试对象交互和空间层次的二阶推理。此外,团队还引入了TreeVGR训练范式,通过强化学习联合监督定位和推理,实现了更准确的定位和可解释的推理路径,证明了可追溯性是推进视觉推理的关键。
核心图片:
(19) 🔥 DreamVLA:用世界知识“做梦”的机器人模型(36 票)
论文原始英文标题:
DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge
论文链接:
https://huggingface.co/papers/2507.04447
简要介绍:
由上海交通大学、清华大学、北京大学、Galbot等机构提出了DreamVLA,一个新颖的视觉-语言-动作(VLA)模型框架。与现有方法预测未来图像不同,DreamVLA通过预测全面的世界知识(包括动态区域、空间深度和语义信息)来进行逆向动力学建模,建立了“感知-预测-动作”的闭环。该方法通过块状结构化注意力机制防止不同知识类型间的干扰,并使用基于扩散的Transformer解码动作。实验表明,DreamVLA在真实机器人和仿真环境中均取得了SOTA性能。
核心图片: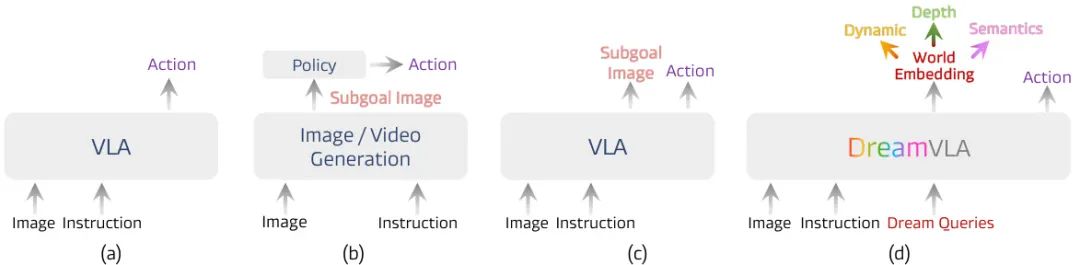
(20) 🚀 POLAR:预训练的策略鉴别器就是通用奖励模型(33 票)
论文原始英文标题:
Pre-Trained Policy Discriminators are General Reward Models
论文链接:
https://huggingface.co/papers/2507.05197
简要介绍:
由上海人工智能实验室和复旦大学的研究者们提出了一个全新的奖励建模视角,将奖励模型(RM)定义为“策略鉴别器”。基于此,他们提出了POLAR(策略鉴别学习)预训练方法,训练RM来识别相同策略并区分不同策略。与依赖绝对偏好的传统方法不同,POLAR捕捉策略间的相对差异,具有高度可扩展性。实验表明,POLAR显著优于传统方法,并在RLHF中表现出强大的泛化能力,同时展现出清晰的缩放定律,为开发通用且强大的RM提供了新方向。
核心图片:
本文由 AI 生成,可能有误
书生大模型体验地址:https://chat.intern-ai.org.cn
-- 完 --
机智流推荐阅读:
1. AI时代,你的速度决定了你的高度:吴恩达YC创业学校万字干货
2. ICCV25 | AI终于分清照片中的前景和背景了!探索南开DenseVLM在密集预测中的区域-语言对齐策略
3. 发个福利,可以免费领WAIC2025(世界人工智能大会·上海)单日门票
4. ICML 2025最佳论文花落谁家?120篇Oral前沿一网打尽!
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
在「机智流」公众号后台回复下方标红内容即可加入对应群聊:
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







