


FastDeploy 2.0:大模型高效部署套件,文心4.5原生,释放最优推理性能!
- 2025-07-29 18:00:00

随着文心4.5系列等优秀大模型的陆续开源,相关学术研究与产业应用竞相涌现。为此,百度正式推出 FastDeploy 2.0,依托飞桨框架,提供大模型高效部署及高性能推理全栈能力!目前,FastDeploy 2.0已支持多个开源大模型的高效部署、支持高性能 EP 并行 PD 分离式部署方案,文心4.5模型输入/输出吞吐可高达56K/21K;并推出效果接近无损的2-bit 量化版本,单卡即可轻松部署千亿参数级模型!FastDeploy 2.0能够帮助企业降低大模型部署门槛、获得最佳推理性能,提高资源调度效率,让更多研究者和企业能够高效部署落地大模型,以满足众多学术研究与产业应用需求。
FastDeploy 是基于飞桨框架研发的面向大语言模型、多模态大模型的推理部署套件,原生支持文心4.5系列开源模型,具备以下特性:
简单易用:兼容 OpenAI 协议,完全对齐 vLLM 使用接口,支持本地和服务化推理,4行代码本地推理,1行命令启动服务。
性能领先:通过各类量化高性能算子、CUDA Graph、投机解码、上下文缓存、分段预填充、PD 分离等高性能优化,在文心及主流开源大模型上性能领先。 量化方法丰富: 权重/激活/KV Cache 支持8-bit、4-bit、甚至极低的2-bit 量化压缩,单卡即可部署千亿级模型。
多硬件推理:支持英伟达系列 GPU、昆仑芯 P800、天数 BI150、海光 K100AI、燧原 S60 等众多硬件上的高效推理。
工业级部署:针对工业部署场景,提供了实时负载感知、分布式负载均衡的流量调度方案。
安装成功后,本地离线使用方式如下:
from fastdeploy import LLM, SamplingParamssampling_params = SamplingParams(top_p=0.95)llm = LLM(model="ERNIE-4.5-0.3B")outputs = llm.chat(messages=[{"role": "user", "content": "把李白的静夜思改写为现代诗"}], sampling_params)
也可以通过一行命令快速启动服务的方式进行推理:
python -m fastdeploy.entrypoints.openai.api_server --model baidu/ERNIE-4.5-0.3B-Paddle --max-model-len 32768 在服务启动后,即可用以下方式请求服务:
curl -X POST "http://0.0.0.0:8180/v1/chat/completions" \-H "Content-Type: application/json" \-d '{"messages": [{"role": "user", "content": "把李白的静夜思改写为现代诗"}]}'
▎GitHub 链接:
https://github.com/PaddlePaddle/FastDeploy
▎文档链接:
https://paddlepaddle.github.io/FastDeploy/
01
极致的单机部署性能
丰富的量化方法:实现多种量化技术,可通过一键命令进行 Weight Only 的8/4-bit 及 FP8在线量化推理,同时支持 W4A8静态量化。基于 CUTLUSS 深度优化算子性能,针对不同硬件和模型可灵活选择最优的方案。
高效的投机解码:实现了高性能、插拔式的投机解码框架,并通过融合 Kernel 加速前后处理、动态批处理、并行验证、虚拟 Padding 加速验证等手段进行性能优化,同时兼容上下文缓存、PD 分离、EP 并行、Chunked-Prefill。针对 MTP 推理,通过 MTP 模块的 Cache KV 进行逻辑、物理地址分离,以支持 Target 模型与 MTP 的多种层级下的上下文缓存功能;通过对 MTP 采取 PD 分离减少通讯量,加速端到端推理性能。
CUDA Graph 优化:支持通过飞桨动转静技术进行图捕获,同时兼容动态图进行整图捕获,在文心轻量级模型上测试,解码速度普遍能够提升2倍以上。
通过上述优化,以 ERNIE-4.5-300B-A47B 模型为例,FastDeploy 支持 Weight Only 4-bit 推理,不仅保证精度无损,还将最小部署的 GPU 数量减少到4张,部署性能相比整体权重8bit 计算的 QPS 提升了约23%,提效的同时还大大降低了硬件资源需求。此外,针对 MoE 量化还引入 W4A8量化和 KV Cache 的8-bit 量化,QPS 进一步提升约40%,在单机 H800上,TPS 领先 vLLM 上单机8卡 WINT4 DeepSeek 198%。

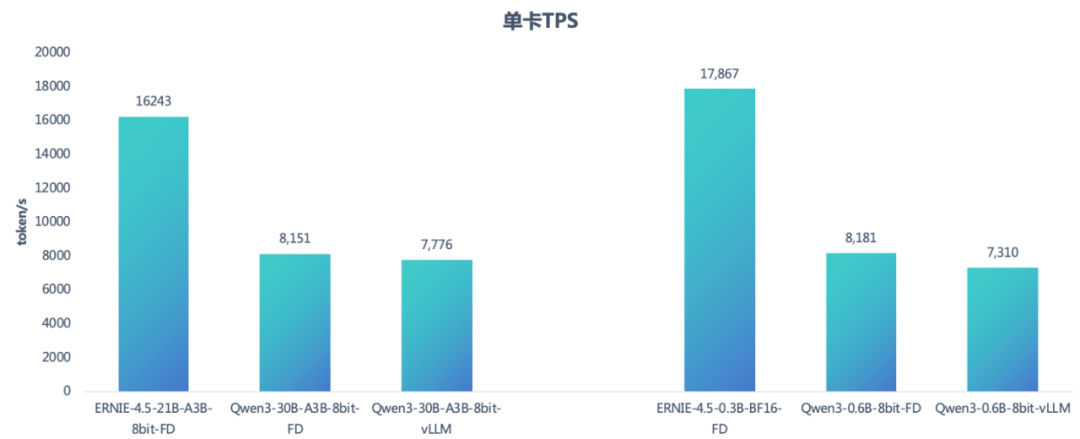
在 ERNIE-4.5轻量级模型上,FastDeploy 也表现出优异的性能,我们和参数规模接近的 Qwen3模型进行性能比较,测试条件为,数据集输入长度1.1K,A3B 模型在 H800上约束 TPOT 不超过25ms,0.3B 及0.6B 模型在 A30上约束 TPOT 不超过16ms,可以看到相同模型 FastDeploy 较 vLLM 性能领先5%、12%,ERNIE 4.5轻量级 MoE 模型分别比 Qwen3对应轻量模型性能快99%、118%(具体数据请见下图)。
02
效果接近无损的2-bit 量化
飞桨2-bit 量化方案将 MoE 权重从 BF16量化到2-bit,从而降低推理时显存占用和推理部署的资源门槛。对于参数量为300B 的 ERNIE-4.5模型,2-bit 量化将权重从600GB 压缩至89GB,使量化后的模型支持141GB H20单卡部署。飞桨2-bit 量化是一种基于卷积编码的量化方法,我们沿用了 Trellis Code Quantization 和 Bitshift Trellis 的思想,并对码本空间和编码算法做了深入改进,不仅减少了量化损失,还提升了推理性能。飞桨2-bit 量化方法比传统的标量量化方法有更好的效果,比传统向量量化有更快的推理速度。经该方案量化压缩的 ERNIE-4.5-300B-A47B 模型,在多个数据集上的精度表现接近无损。

FastDeploy 支持 ERNIE-4.5 2-bit 量化模型的推理部署,提供高性能的2-bit Group-GEMM 算子,该算子支持寄存器级别的权重数据解码和反量化,构建了 warp 级别的“访存-解码-反量化-计算”的高效执行流水线,在极大降低访存量的同时,快速进行解码和反量化。除此之外,为了进一步提升推理性能,我们还支持2-bit 权重的离线重排序、快速数据类型转换等优化,后续将逐步开源。
03
高性能的大规模分布式推理
FastDeploy 通过专家并行(Expert Parallel)以支持 MoE 的大规模分布式推理,目前已支持 ERNIE-4.5-300B-A47B 大规模分离式部署。我们使用 DeepEP 执行卡间、机间的 Dispatch 和 Combine 操作。我们对 DeepEP 的低时延模式进行了两阶段改进并进行了细致的优化,通信性能可提升2倍。

该方案可以简单表述为,当命中本机的专家索引时,直接使用 NVLINK 进行传输;当命中其他机器的专家索引时,采用两阶段传输,第一阶段使用 RDMA 传输到目标机器的相同 rank 上,第二阶段使用 NVLINK 在目标机器传输到目标卡上。但是在实现中,低时延模式为了避免引入 CPU 同步,无法提前发送元信息,各个阶段的设计复杂度过高;同时,卡内、卡间、机间涉及阶段多且数据方向耦合,简单的内存序设计会带来性能劣化,需细致考虑内存一致性。因此,我们针对无元信息,在 kernel 中通过3级、共7种原子化的信号量映射完成了无元信息的传输设计,针对内存一致性控制,我们在各个阶段精细使用 SM 层、GPU 层、系统层内存一致性模型控制内存序,避免不必要的性能损失的同时保证了传输的正确性。
针对 KVCache 传输,自研了一套基于 RDMA 的传输库,部署简单轻量,仅需基础的 RDMA 运行环境即可使用。此传输库支持 Nvidia GPU,也支持昆仑芯 XPU。为了实现更好的性能,FastDeploy 中的实现与现有的解决方案不同,包括减少 CQE 数量和支持 PCIe Relaxed Ordering。在 Mellanox ConnectX-7 400G 网卡上测试,多压力线程场景下,FastDeploy 中的实现和 Mooncake 实现都能够充分的利用网卡带宽,达到接近网卡硬件理论极限的传输性能。单压力线程测试,与 Mooncake 传输引擎相比,性能提升1.1倍到6.9倍,详细可参考文档。
▎文档
https://github.com/PaddlePaddle/FastDeploy/blob/develop/fastdeploy/cache_manager/transfer_factory/kvcache_transfer/README_CN.md

ERNIE-4.5-300B-A47B 模型经过 W4A8量化、KVCache 量化、通信优化、KV Cache 传输优化、MTP 投机解码推理等优化,输入2K 输出400的数据集,在 H800硬件上保持 TPOT 50ms,输入/输出 TPS 高达56K/21K,相比 ERNIE 4.5技术报告中输出 TPS 再提升17%,在此基础上我们仍然还在做一些算子优化,后续会陆续发布。
04
实时负载感知、分布式负载均衡调度
通常推理任务的输入长度不同,输出长度也和实际的推理任务相关,无法提前确定。当前面向负载进行调度的开源实现方案一般基于 round robin 或者输入长度进行调度,无法真正保证推理集群动态输出时的全局负载均衡。FastDeploy 基于 Redis 实现了实时感知全局负载、分布式负载均衡调度策略,无需单独部署,通过启动参数即可开启,可以进一步优化集群吞吐和 TTFT 指标。
PD 混合部署场景下,调度器基于推理实例主动拉取+Work Stealing 策略进行负载均衡,每个推理实例在 Redis 拥有一个任务队列,集群中的空闲节点会窃取高负载节点的任务进行推理,有效解决集群中的负载长尾问题,提升服务整体性能表现。
PD 分离场景下,调度器实现为分布式调度器,推理实例通过 Redis 注册实例信息并周期性上报实时负载来更新存活状态,调度器通过 Redis 实时感知集群负载。调度过程中,首先根据推理请求的输入 token 数量来动态划定低负载节点集合,然后从中随机选择一个节点进行调度,这样可以缓解一个同步周期内不同的调度器将请求调度到同一实例上引起的负载波动。

05
广泛支持多硬件,适配成本低
目前开源社区的大模型部署工具大多针对 Nvidia GPU 和 AMD GPU 提供支持,而 FastDeploy 除了充分考虑 Nvidia GPU 的优化特性外,充分考虑多硬件的部署需求。为此我们提供了 FastDeploy 硬件适配层,具备屏蔽不同硬件间的差异、统一模型调用接口、高效适配多种设备后端、Kernel 支持 CUDA/Triton/C++多种不同实现。
支持昆仑芯 P800、天数 BI150、海光 K100AI、燧原 S60等众多硬件的高性能推理,近期还会持续扩展。以在昆仑芯 P800部署 ERNIE-4.5-300B-A47B-Paddle 模型为例,通过如下步骤快速完成部署,详细请见参考文档:
# 步骤1. 基于预编译镜像创建并进入容器mkdir Workcd Workdocker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/fastdeploy-xpu:2.0.0docker run --name fastdeploy-xpu --net=host -itd --privileged -v $PWD:/Work -w /Work \ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/fastdeploy-xpu:2.0.0 \/bin/bashdocker exec -it fastdeploy-xpu /bin/bash# 步骤2. 基于 ERNIE-4.5-300B-A47B-Paddle 模型启动 OpenAI API 协议兼容服务export XPU_VISIBLE_DEVICES="0,1,2,3" 或 "4,5,6,7"python -m fastdeploy.entrypoints.openai.api_server \--model baidu/ERNIE-4.5-300B-A47B-Paddle \--port 8188 \--tensor-parallel-size 4 \--max-model-len 32768 \--max-num-seqs 64 \--quantization "wint4" \--gpu-memory-utilization 0.9# 步骤3. 使用 curl 发送示例请求curl -X POST "http://0.0.0.0:8188/v1/chat/completions" \-H "Content-Type: application/json" \-d '{"messages": [{"role": "user", "content": "Where is the capital of China?"}]}'
最后,在人工智能技术爆发式增长的今天,我们坚信开源协作是推动大模型普惠化、工程化落地的核心力量,我们期待广大开发者加入 FastDeploy 开源社区,共创 AI 推理的未来!
06
丰富配套,开源共享
实测活动:FastDeploy 2.0推理部署实测专题活动已同步上线,基于 FastDeploy 2.0解锁文心4.5系列等开源模型的推理部署等能力,即可获得骨瓷马克杯等 FastDeploy 2.0官方周边、APPLE 代金卡、以及丰富奖金支持!欢迎大家体验反馈。
▎传送门:
https://www.wjx.top/vm/meSsp3L.aspx#





 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





