


Qwen首次公开强化学习核心算法,超越字节GRPO
- 2025-07-28 14:42:10
时令 发自 凹非寺
量子位 | 公众号 QbitAI
通义千问一周开源三连暴击,背后杀手锏官方来揭秘了:
强化学习新算法GSPO。
同等算力下,训练效率碾压GRPO,准确率和性能飙升。
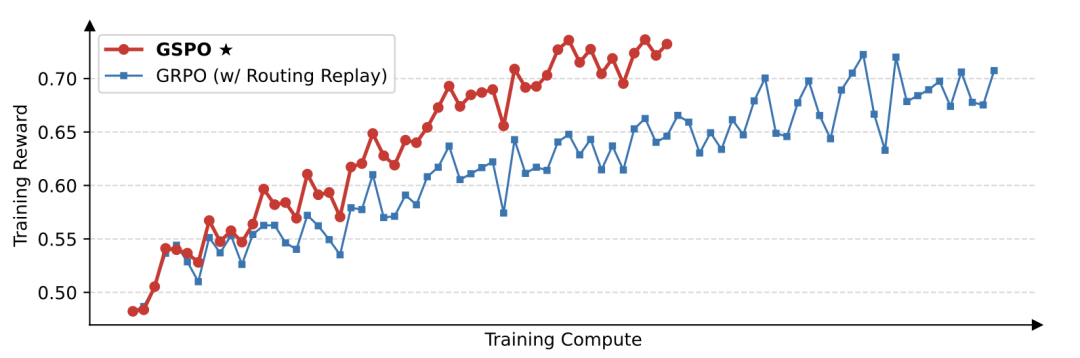
背后的核心创新在于:GSPO定义了序列级别的重要性比率,并在序列层面执行裁剪、奖励和优化。
此算法一出,便迅速引发了人们对其在其他模型中应用效果的期待。

序列级优化目标
相较于GRPO,GSPO有三大突出优势:
强大高效:GSPO具备显著更高的训练效率,并且能够通过增加计算获得持续的性能提升;
稳定性出色:GSPO能够保持稳定的训练过程,并且根本地解决了混合专家(Mixture-of-Experts,MoE)模型的RL训练稳定性问题;
基础设施友好:由于在序列层面执行优化,GSPO原则上对精度容忍度更高,具有简化RL基础设施的诱人前景。
而这一切优势的背后,正是GSPO在设计上所引入的序列级优化目标。
设 为查询,
为查询, 为用于采样回复的策略,
为用于采样回复的策略, 为采样得到的回复组,
为采样得到的回复组, 为各个回复的组内相对优势,
为各个回复的组内相对优势, 为需优化的当前策略。
为需优化的当前策略。
GSPO采用以下优化目标:
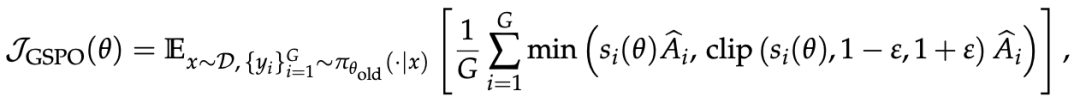

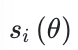 即为GSPO基于序列似然定义的重要性比率,其中研究人员进行了长度归一化以降低方差并统一
即为GSPO基于序列似然定义的重要性比率,其中研究人员进行了长度归一化以降低方差并统一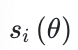 的数值范围。
的数值范围。
GSPO裁剪token比例超GRPO百倍
实验中,研究人员选用了基于Qwen3-30B-A3B-Base微调得到的冷启动模型,并在AIME’24、LiveCodeBench和CodeForces等多个权威基准任务上测试其性能。
值得注意的是,GRPO必须采用Routing Replay训练策略才能正常收敛,而GSPO则无需该策略。
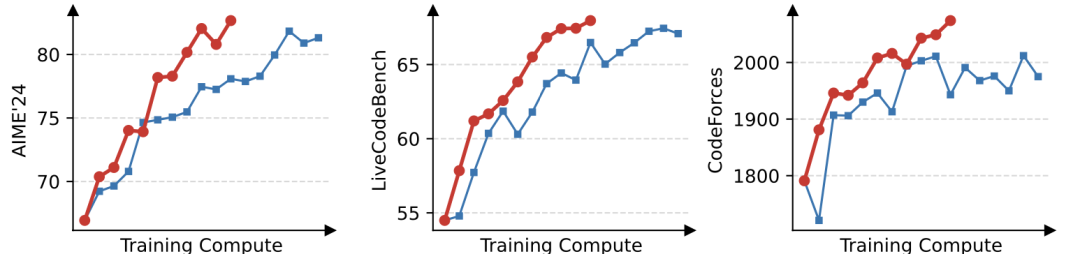
从上图可见,GSPO表现出比GRPO更高的训练效率,即在同等计算开销下能够取得更优的性能。
特别地,他们还观察到GSPO可以通过增加算力来获得持续的性能提升——这正是他们所期待算法的可拓展性。
最终,他们成功地将GSPO应用于最新的Qwen3模型的大规模RL训练,进一步释放了RL scaling的潜能!
还有个有趣的观察,GSPO所裁剪的token比例比GRPO要高上两个数量级,但却具有更高的训练效率。
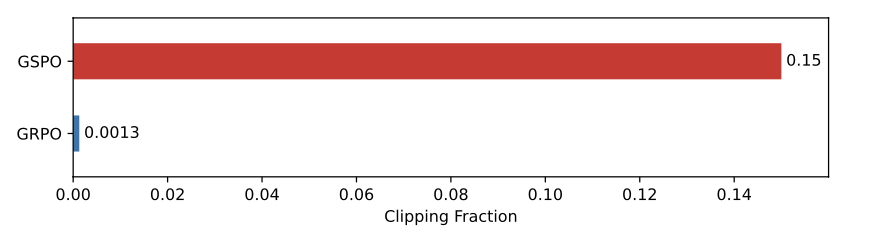
这进一步表明,GRPO所采用的token级优化目标存在噪声大、效率低的问题,而GSPO的序列级别的优化目标则提供了更可靠、有效的学习信号。
在使用GRPO训练时,MoE模型的专家激活波动性常导致RL训练无法正常收敛。
为了解决这一挑战,研究者过去采用了路由回放(Routing Replay)训练策略,即缓存 中激活的专家,并在计算重要性比率时在
中激活的专家,并在计算重要性比率时在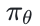 中“回放”这些路由模式。
中“回放”这些路由模式。

上图可见,Routing Replay对于GRPO训练MoE模型的正常收敛至关重要。然而,这种做法会产生额外的内存和通信开销,并可能限制MoE模型的实际可用容量。
因此,GSPO的一大突出优势在于彻底消除了对Routing Replay的依赖。其核心在于:GSPO仅关注序列级别的似然(即 ),而对个别token的似然(即
),而对个别token的似然(即 不敏感。
不敏感。
正因如此,GSPO无需Routing Replay等对基础设施负担较大的手段,既简化和稳定了训练过程,又使得模型能够最大化地发挥容量与潜能。
此外,由于GSPO仅使用序列级别而非token级别的似然进行优化,直观上前者对精度差异的容忍度要高得多。
这使得GSPO可直接使用推理引擎返回的似然进行优化,从而无需使用训练引擎重新计算。该特性在partial rollout、多轮RL以及训推分离框架等场景中特别有益。
论文链接:https://www.arxiv.org/abs/2507.18071
参考链接:
[1]https://mp.weixin.qq.com/s/Y5pfNNX4K6k0hfxXr87dkQ
[2]https://x.com/Alibaba_Qwen/status/1949412072942612873
[3]https://x.com/QGallouedec/status/1949454865442193779
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





