


多模态卷王阶跃星辰Step 3登场,推理效率可达DeepSeek-R1 300%
- 2025-07-26 15:01:48

新智元报道
新智元报道
【新智元导读】新一代多模态推理基模Step 3横空出世了!是专为推理时代打造的最适合应用的模型,以最高可达DeepSeek-R1 300%的推理效率击破行业天花板。7月31日,Step 3将正式开源,问鼎开源最强多模推理模型。
2025年,AI模型到底有多卷?
谷歌和OpenAI从年初开始「打生打死」,发布会一场接一场,最近OpenAI更是为了和谷歌DeepMind争夺「IMO金牌第一推理模型」互相撕脸。

闭源模型们神仙打架,开源模型却是「格局已变」。
开源模型这块,国内已经快一枝独秀了,DeepSeek、Qwen、StepFun、Kimi K2等成为海外讨论的焦点。
曾经的开源之光Meta的Llama已经被人遗忘,逼得扎克伯格顾不得体面疯狂挖人。
喧嚣之后:什么才是真正「好用」的AI模型?
时至今日,整个行业都意识到,真正的问题是,到底什么样的模型才能真正服务于千行百业,而不仅仅是刷新各个Bench的榜单。
遗憾的是,放眼望去,能同时满足「开源」,又能提供「多模态能力」,还能「推理」的模型,还真的数不出几个,更别说好用了。
2025 WAIC大会上,阶跃星辰的新一代主力基座模型Step 3,带来了意想不到的惊喜。


新一代旗舰基模Step 3的发布,标志着阶跃多模态大模型又一个新里程碑。
它采用了原创MFA架构,通过模型和系统联合创新,实现了行业领先的推理效率、极致性价比。
要说Step 3的核心亮点,可以概括为四个字——「多开好省」。
具体来说,多代表「多模态」,开代表「开源」,好代表「强智能」,省代表「低成本」。
接下来,就我们一一拆解,这四大维度背后代表的真正含义。
作为AI界「多模态卷王」,阶跃首发的Step 3综合实力究竟有多强?
Step 3在MMMU、MathVision、SimpleVQA、AIME 2025、LiveCodeBench(2024.08-2025.05)等榜单上直接拿下了开源多模态推理模型的SOTA成绩。

榜单成绩刷的再高,不如真正拉出来遛一遛。

现在,直接进入阶跃AI的网页版和手机版,即可开启Step 3的最新体验。

传送门:https://www.stepfun.com/chats/new
在视觉推理实测中,Step 3能够对图片中的细节,充分理解到位。
比如,扔给阶跃AI一张猫咪图,并问「图片里有几只猫」?

Step 3思考后给出回复,一眼识别出「一只猫+影子」,并给出了导致视觉错觉的原因。

再上一个难度测试,当你看到如下这张图后,能否发现图片中写了什么?
别说AI了,眼神不太好的人,硬是盯半天也不一定能看出来。

Step 3经过长时间推理后,一步一步解读出图片中从上至下的字母,并将其组合成「AI MAKE LIFE BETTER」的正确答案。

上下滑动查看
再比如,正在减肥期间的你,想要随时监测食物卡路里,同样交给Step 3就可以了。
上传一张食物订单图,提问「2个人一餐吃了这些,人均摄入多少卡路里」?

不一会儿功夫,Step 3就给你算的明明白白。

上下滑动查看
再来个经典视觉难题「吉娃娃还是松饼」,堪称AI视觉领域的「图灵测试」,曾难倒了不少大模型。
那么,Step 3的表现又如何呢?

令人惊喜的是,经过缜密的思考之后,Step 3准确列出了图中所有吉娃娃的所在位置。

上下滑动查看
再比如室友小聚,需要AA制但又懒得分账时,可以把相关图片上传给Step 3。
一张聊天截图,一张购物单,问下每个人均摊多少?

在仔细推敲之后,Step 3针对5个人的花费给出了详细的解答。

更重要的是,这充分体现了Step 3「多开好省」的核心亮点。
这四大维度,对于用户来说至关重要。
人们在选择模型时,这一过程就好比「木桶理论」,不仅要关注模型的单一优势,而是要综合考量多维度的整体表现。

作为阶跃首个全尺寸、原生多模态推理模型,Step 3非常适合落地应用。
一直以来,数学、代码成为业界考验模型能力的重要方向,但在实际应用中,多模态才是真正的刚需。
谷歌DeepMind CEO Hassabis曾在公开演讲中提到,「原生多模态模型是通向AGI的关键」。

也就是说,未来的AI系统需要超越单一模态,真正理解和整合多种感官信息,才能在复杂场景中发挥作用,从「实验室标杆」走向「产业刚需」。
在「性能好」方面,Step 3不仅知识丰富,还具备了严谨的逻辑和多步推理能力,满足了强化学习范式下,对强大推理能力的需求。
发布会上,阶跃官宣,预计7月31日,Step 3将面向全球企业和开发者开源。
如此强大的多模态推理模型开源后,意味着企业和开发者都可以基于自身条件进行私有化部署,对其进行训练和微调。
Step 3的另一大杀手锏,便是对所有芯片友好。这也是「省」一大特点背后的关键因素。
要降低推理模型的成本,核心要素是提高解码效率。
市面上的主流开源模型,虽然针对解码做了大量优化,但这些优化方案主要适配国际高端芯片,在中端及国产芯片上的解码效率仍有提升空间。
为了突破这点,Step 3进行了系统性的技术创新,在架构设计阶段就充分考量了系统与硬件的特性,能够实现广泛硬件平台上的高效推理,解码效率达到行业领先水平。
根据原理分析,Step 3在国产芯片上的推理效率最高可达DeepSeek-R1的300%。
在基于NVIDIA Hopper 架构的芯片进行分布式推理时,实测Step 3相较于DeepSeek-R1的吞吐量提升超70%。

这意味着Step 3具备广泛的普适性,在各种硬件环境下部署,都能大幅降低推理成本。
那么Step 3究竟采用了怎样的技术架构,才能实现如此卓越的多模态推理能力与成本效率?

大模型技术发展至今,尤其是在长上下文推理任务中,大部分模型都面临较低的解码效率。
Step 3能做到「大而实惠」,得益于阶跃星辰在软硬件协同设计优化,这是模型和硬件平衡的艺术。

Step 3在国产芯片上的推理效率最高可达DeepSeek-R1的300%,且对所有芯片友好。
在基于NVIDIA Hopper架构的芯片进行分布式推理时,实测Step 3相较于DeepSeek-R1的吞吐量提升超70%。
Step 3总共拥有316B参数,激活参数为38B。此外还有一个5B参数的视觉编码器。
对于FFN前馈神经网络,Step 3采用了受到DeepSeekMoE启发的共享专家设计。
对于MFA,Step 3配置了64个注意力头,KV维度256,Query维度2048。

Step 3能够实现高性价比(高成本效益)的解码,其核心在于一套深度集成的模型-系统协同设计 (model-system co-design) 理念。

Step 3的推理系统,可能是首个利用注意力-前馈网络解耦(Attention-FFN Disaggregation,AFD)理念并实现高吞吐量解码的生产级服务系统之一。
AFD是Step 3实现高效解码的系统级基石。
它将传统大语言模型中交错的Attention层和FFN(前馈网络)层在物理上分离开,部署到不同的专用GPU集群上。
这种架构上的分离使得每个子系统可以采用最适合其计算特性的不同并行策略。
在处理4K平均上下文长度的特定场景下,Step 3仅需32个GPU,远少于DSv3在类似任务中所需的128个GPU。
当上下文长度为8K,Step 3的理论解码成本最低。每1M解码token的成本约为0.055美元。
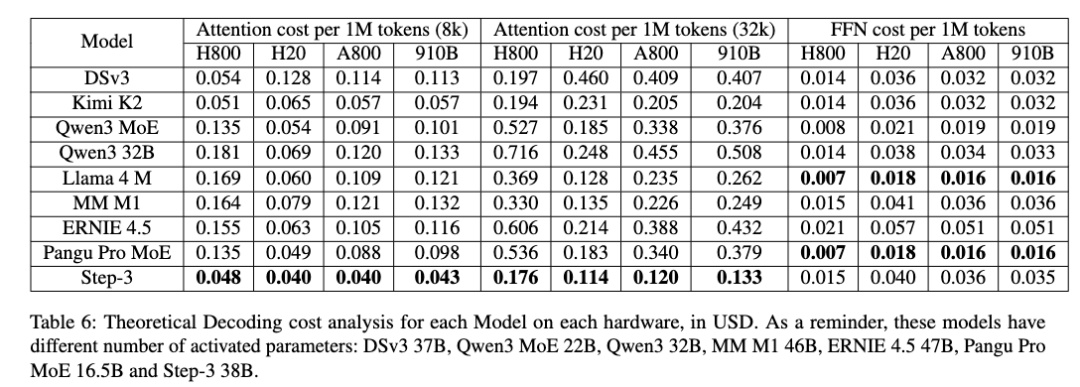
各模型在不同硬件上的理论解码成本分析(单位:美元)。注意:这些模型的激活参数数量不同:DSv3 37B,Qwen3 MoE 22B,Qwen3 32B,MM M1 46B,ERNIE 4.5 47B,Pangu Pro MoE 16.5B和Step 3 38B

不同模型和推理配置的解码成本(每1M个token)
Step 3在非Hopper系列的廉价硬件上依然保持很高的成本效益。

计算强度(Arithmetic Intensity)指计算操作与内存访问字节数的比率。
Step 3的MFA的算术强度设计为128,这使得它能更好地匹配各类加速器(如A800、910B)的硬件特性,避免了因算力或带宽的单一瓶颈而导致效率低下。
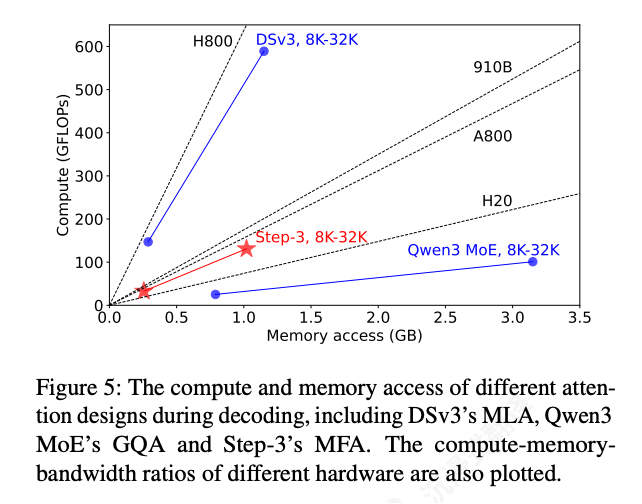
解码过程中不同注意力设计的计算和内存访问
Step‑3的MFA同时实现了低计算和内存访问。
上图显示它的所需计算量是DSv3的四分之 一,其所需内存访问量是Qwen3的三分之一。
使用AFD,注意力机制和FFN组件都可以分别轻松扩展。

AFD架构中的模块解耦。FFN可以部署在TP-only、 EP-only或混合TP+EP的方式,具体取决于硬件和模型架构
这为利用非旗舰硬件进行注意力部分或FFN部分的处理创造了更多机会。

此外,Step 3还为AFD量身定制了高性能AF通信库StepMesh。

上图展示了为AFD量身定制的StepMesh通信工作流程:
1) 异步 API 和专用线程;
2) 基于CPU的操作执行;
3) 预注册张量以实现高效通信。

用于多个加速器的StepMesh框架
上图展示了StepMesh框架,该框架设计为高度可扩展的架构,能够集成新型加速器。
此框架将加速器视为后端,并建立了一组用于AFD通信的关键后端接口。
这些接口涵盖了内存分配和流同步等核心功能。
通过遵循这些定义良好的接口,新型加速器可以轻松集成到StepMesh框架中。
StepMesh实现了异构加速器之间的无缝通信,不同类型硬件都能够高效协作。

阶跃星辰虽然仅成立两年多,但其实已经是名副其实的「多模态卷王」。

随着Step 3发布,阶跃也构建起独创的「1+N」的 Step 系列大模型矩阵,持续突破技术边界。
「1」是指Step 3基础大模型;「N」则为Step系列的多模态大模型矩阵,广泛覆盖语音、视觉理解、图像编辑、图像和视频生成、音乐等领域。
本次WAIC期间,阶跃升级了多模态模型,包括阶跃首个多模理解生成一体化模型Step 3o Vision,第二代端到端语音大模型Step-Audio 2,都可以在「阶跃AI」官网(stepfun.com)和「阶跃AI」App进行体验。
我们浅玩了一下「阶跃AI」的视频通话功能后发现,真有点钢铁侠里「贾维斯」那味儿了。
它可以开启摄像头,观察周围环境,还能识别环境中的复杂物体。
比如可以识别出套着黑色外壳的苹果耳机,也可以在白色桌面上识别出透光的眼镜。
即使在环境光强反射下,依然能够稳定识别全英文包装的药品。
可以一字不差的检测出手里拿着的是「BLACKMORES」鱼油品牌,并且还准确给出了产品功效的解读。
成立两年多以来,Step系列已经发布了26款自研基座模型,多模态占比超七成,而且模型性能也保持着行业的顶尖水平。
在不断追求模型智能上限的同时,阶跃也在持续探索着模型的落地应用。
与其他厂商只发模型不同,Step 3更进一步,实现了商业价值的大幅联动。阶跃认为要让大模型真正用起来,不仅仅是训练一个模型,需要全产业链的联合创新。
在发布会现场,阶跃星辰宣布联合近 10 家芯片及基础设施厂商,共同发起「模芯生态创新联盟」,致力于打通芯片、模型和平台全链路技术。
通过底层联合创新提升大模型适配性和算力效率,该联盟将为企业和开发者提供高效易用的大模型解决方案,加速应用落地。
首批成员包括华为昇腾、沐曦、壁仞科技、燧原科技、天数智芯、无问芯穹、寒武纪、摩尔线程、硅基流动等。
目前,华为昇腾芯片已首先实现Step 3的搭载和运行。沐曦、天数智芯和燧原等也已初步实现运行Step 3。其它联盟厂商的适配工作正在开展。

阶跃的AGI之路并不单纯追求炫技,而是在每一代模型的研发中都思考如何让大模型真正用起来,无论是寻求突破系统级创新,还是联合全链条技术产业一起探索更底层的协同创新。
阶跃星辰创始人、CEO 姜大昕说,「从Step 1到Step 2两代基模的快速迭代,促使我们深入思考什么才是最适合应用的模型。随着大模型进入到强化学习发展阶段,新一代推理模型成为主流,模型性能的提升固然显著,但这是否完全等同于模型价值?面对这一产业之问,我们必须回归客户需求,立足真实应用场景,探索模型创新落地的可行路径。这是我们研发新一代Step 3基础模型的出发点」。
在通往AGI征程中,阶跃星辰正以开拓者之姿,引领中国AI驶向更广阔的星辰大海。


 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





