在基于脑电的情感识别领域,标签稀缺性问题是当前的主要挑战之一。在该论文中,作者提出了一种新的半监督迁移学习框架(EEGMatch)来利用标记和未标记的EEG数据。首先,开发了一种基于EEG-Mixup的数据增强方法,以生成更多用于模型学习的有效样本。其次,提出了一种半监督两步成对学习方法来桥接原型和实例成对学习,其中原型成对学习测量EEG数据和每个情感类的原型表示之间的全局关系,实例成对学习捕获EEG数据之间的局部内在关系。第三,引入半监督多域自适应来对齐多个域(标记源域、未标记源域和目标域)之间的数据表示,其中分布不匹配的情况得到缓解。作者在三个基准数据集(SEED、SEED-IV和SEEDV)上进行了广泛的跨被试实验(留一受试者)。结果表明,在不同的不完整标签条件下,所提出的EEGMatch表现优于最先进的方法(对SEED的改进为5.89%,对SEED-IV的改进为0.93%,对SEED-V的改进为0.28%),证明了其方法的有效性。
现有的基于脑电的情感识别研究大多基于传统的监督学习,其中训练集中的所有数据都被很好地标记。但是,标记数据通常难以获得、昂贵且耗时,需要巨大的人工努力。另一方面,与标记数据相比,未标记数据更容易收集。与监督学习相比,使用标记和未标记数据的半监督学习可以花费更少的人力,用小标记训练数据可以解决建模问题,并创建更具泛化性的模型。然而,如何设计算法来高效和有效地利用标记和未标记数据的存在来改善模型学习,是当前基于半监督EEG的情感识别中的一个关键挑战。
在现有的基于监督EEG的情感识别研究中,迁移学习方法已被广泛采用以最小化EEG信号中的个体差异,其中来自训练受试者的标记数据被视为源域,来自测试受试者的未知数据被视为目标域。通过对齐源域和目标域的联合分布以近似满足独立同分布(IID)假设,可以减轻EEG信号中的个体差异,并且可以增强目标域上的模型性能。当前使用迁移学习方法的基于脑电的情感识别研究中,通常需要在源域中大量的标记数据。如果源域中的大多数数据未被标记,则模型训练性能将受到严重限制。半监督学习框架通过利用少量标记数据和大量未标记数据的组合以及增强学习任务,为解决这一问题提供了巨大的潜力。但是,在前人的工作中,仍有三个局限性,应在未来基于半监督脑电图的跨被试情绪识别研究中彻底调查和解决。
1)不适当的脑电信号数据增强:先前的研究利用Mixup方法进行脑电信号数据增强,该方法忽略了脑电信号的非平稳特性。在不同试验中从不同受试者收集的EEG样本并不满足IID,这与Mixup方法的主要原则相矛盾。
2)不完整标签任务的低效学习框架:以前的工作基于逐点学习框架,该框架依赖于丰富和精确的标签进行模型训练,在标签稀缺条件下不切实际。
3)忽略标记和未标记源数据之间的分布不匹配:以往的模型只考虑了标记源数据和未知目标数据之间的分布不匹配,未标记源数据的分布比对被忽略。
为了解决上述问题,作者提出了一种新的半监督学习框架(EEGMatch),用于基于EEG的不完整标签的跨被试情感识别。所提出的EEGMatch由三个主要模块组成:基于EEG-Mixup的数据增强、半监督两步成对学习(原型和实例)和半监督多域自适应。
作者提出的 EEGMatch 的半监督学习框架由三个模块组成。(1) 基于 EEG‑Mixup 的数据增强:生成增强数据并增加建模的样本量。(2) 半监督两步成对学习:在考虑全局特征表示(原型方式)和局部内在关系(实例方式)的情况下提升特征学习。(3) 半监督多域自适应:对标记源域 (S)、无标记源域 (U) 和目标域 (T) 之间的分布偏移进行对齐。

图1 EEGMatch的整体方法表示
(1) 基于 EEG‑Mixup 的数据增强:
EEG-Mixup数据增强方法的核心思想是针对脑电信号的非平稳特性,设计符合IID假设的增强策略。作者的方法通过两个关键步骤实现:有效数据采样严格限定混合素材的来源范围,仅选取同一受试者、同一次试验内的EEG片段(如SEED数据集中1秒时长的差分熵特征),确保数据满足独立同分布要求,避免跨主体或跨试验混合导致的分布偏移;领域自适应混合采用带权线性插值技术,对标记源域(S)随机选取同次试验的两个样本,通过加权融合生成新样本并保留情感标签的一致性(因同次试验样本共享标签),而对未标记源域(U)和目标域(T)则仅混合信号本身生成无标签增强数据。最终,各领域的增强数据与原始数据拼接,显著扩充训练样本规模。该方法通过针对性解决EEG信号特性与传统数据增强的矛盾,为后续模型训练提供了高质量、分布一致的增强数据。
(2) 半监督两步成对学习:
该模块的核心是设计一个双步成对学习策略,以解决传统点监督学习在标签不足时的局限性。它分为两个互补阶段:原型级学习聚焦于全局情感类别的代表性特征,而实例级学习则强化样本间的局部关系。这种结构充分利用了标记和未标记数据,通过半监督机制生成可靠的监督信号,提升模型在跨受试者场景下的鲁棒性。
原型级学习旨在构建每个情感类别的原型表示,作为全局参考基准。其思想是通过半监督方式融合标记数据和未标记数据的信息。具体来说,首先为未标记源域样本生成伪标签:使用分类器输出预测概率,并通过Sharpen函数调整置信度以最小化熵值。这些伪标签与真实标签结合,共同参与原型的计算过程。原型本身通过双线性相似度度量来建立样本与类中心的关系,确保特征表示能紧密对齐情感类别结构。这一步的关键创新在于,即使标签稀缺,也能通过伪标签扩展数据参与范围,避免原型估计偏差。
实例级学习专注于捕捉样本间的内在局部结构(如相似样本的聚集性和差异样本的分离性),以增强特征的判别力。其思想是通过动态和渐进式策略处理未标记数据的不确定性。在源域(含标记和未标记样本),计算实例间相似度矩阵,基于伪标签构建监督关系矩阵作为训练目标。在目标域(无标签数据),引入动态阈值机制:仅选择高置信度样本对或低置信度样本对参与损失计算,中间模糊样本被忽略以过滤噪声。同时,采用渐进式学习策略:在训练过程中逐步调整阈值范围(初始值固定,后期逐渐扩展),逐步纳入更多可靠样本对,增强模型稳定性。
(3) 半监督多域自适应
该模块提出一种半监督多域自适应方法,核心思想是通过理论推导建立目标域误差上界与三域分布差异的关联性,据此设计联合优化策略。具体实现包含三个关键机制:首先构建三域判别器,通过梯度反转层(GRL)实现对抗训练,最大化域分类损失以对齐标记源域(S)、未标记源域(U)和目标域(T)的特征分布(最小化域间H-散度);其次复用实例级成对损失约束源域特征,提升分类判别性;最后引入动态权重系数协调对抗训练与特征学习的平衡,初期侧重特征提取后期强化域对齐。该方法突破传统域自适应仅对齐S与T域的局限,首次实现三域联合分布优化,理论驱动和对抗机制的结合显著提升跨域泛化能力。
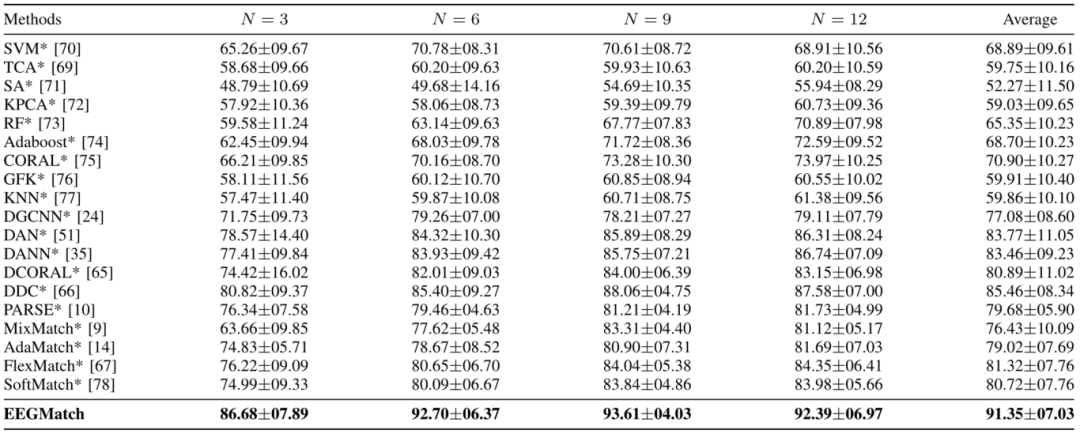
表I报告了在SEED数据集上的实验结果,对于每个受试者,N个试验有标签,15-n个试验没有标签。复现的模型结果用“*”表示,与现有流行的机器学习或深度学习方法进行了比较。结果表明,在不同的不完整标签条件下,与其他模型相比,所提出的EEGMatch获得了更好的性能,其中N=3、6、9、12的平均模型性能为91.35±07.03。与文献中最佳竞争对手实现的性能相比(DDC:85.46±08.34),不同N值下的平均性能提高为5.89%。它表明,即使只有少量的标记数据(当N较小时),EEGMatch仍然可以很好地利用标记源数据(S)和未标记源数据(U)来增强模型泛化能力,并在目标域(T)中达到令人满意的情感识别性能。表II和表III报告了在不同不完全标签条件下在SEED-IV和SEED-V数据集上的实验结果,这也显示了所提出的EEGMatch在半监督跨被试情感识别任务上的优越性。具体来说,SEED-IV数据集上N=4、8、12、16、20的平均模型性能为65.53±08.31。此外,在N=5,15的SEED-V数据集上的平均模型性能为62.75±09.02。与文献中的最佳结果相比,SEED-IV数据集在不同N值下的平均性能增强为0.93%(DDC:64.60±08.82),SEED-V数据集为0.28%(DDC:62.47±08.25)。另一方面,在两个数据集上的实验性能提升不如在SEED数据集上明显。一个可能的原因是数据集中更多的情感类会使预测的伪标签)更加不稳定。
表I 在具有不完整标签的SEED数据集的平均准确率(%)和标准偏差(%)
表II 在具有不完整标签的SEED-IV数据集的平均准确率(%)和标准偏差(%)

表III 在具有不完整标签的SEED-V数据集的平均准确率(%)和标准偏差(%)
在本文中,作者提出了一种新的半监督学习框架(EEGMatch),用于基于EEG的不完全标签的跨被试情感识别。所提出的EEGMatch引入了一种高效的基于EEG-Mixup的数据增强来增加建模的样本量,开发了一种半监督两步成对学习框架(原型和实例)来实现高效的全局和局部特征学习,并提出了一种半监督多域自适应方法来共同解决多域之间的分布不匹配问题。在各种标签稀缺条件下,根据实际实验方案,在两个基准数据集(SEED和SEED-IV)上进行了广泛的实验。与现有流行的机器学习和深度学习方法相比,实验结果证明了所提出的EEGMatch在处理具有不完整标签的半监督EEG应用方面的优越性。


















 扫码添加微信
扫码添加微信



