


用户暴涨近300万,国产AI音乐神器Mureka重磅升级V7,我们拿它复刻了「印度神曲」
- 2025-07-23 16:57:15
机器之心编辑部
AI 正悄悄「攻占」你的歌单。
前几天在网易云音乐上瞎逛,被意外种草一首歌,真一开口就是月色迷蒙的味道。
目前,该歌曲拿下了 15 万小红心。本想看看是哪位大神的作品,没想到底下一水的评论:这是 AI 生成的!

其实细听之下还是能找出「端倪」的,比如音质糊的像画面马赛克、人声跟牙齿漏风似的。但经过持续的进化,AI 音乐越来越真假难辨。
现在,AI 音乐的这把火,越烧越旺。
7 月 23 日,大模型厂商昆仑万维正式发布了新一代音乐大模型 Mureka V7,成为了当前国产最强,并在多个关键指标上显著超越海外 AI 音乐平台 Suno(V4.5),包括平均表现评分、混音质量与质感、人声真实感与表现力、整体音质评价。
不仅如此,与上一版本 V6 相比,Mureka V7 生成的音乐品质更高,不仅大幅提升旋律动机和编曲质量,还进一步增强了人声与乐器真实度。

这么说吧,即使你是个五音不全的音乐小白,也能拿它做出超细腻的个人独家 BGM。而对于专业的音乐人而言,Mureka V7 生成的音乐又极具创新性,在一定程度上可以启发灵感。
Mureka V7 作品《杜甫》
目前,Mureka V7 已经全面上线,感兴趣的小伙伴可以前往官网进行体验。

官网地址:https://www.mureka.cn/
接下来,我们就来实测一下,看看 Mureka V7 在搞音乐创作时是否还有那种「牙齿漏风」的感觉。
一手实测
能模仿王菲,还能生成「土味」MV
Mureka V7 真不只是「AI 帮你写首歌」那么简单,现在它还上线了新功能 —— 自定义歌手。
我们可以上传音频,或者直接丢一个视频链接进去,AI 就能自动模仿音色,唱出全新创作的歌曲。
以天后王菲为例。众所周知,王菲是邓丽君的铁杆粉丝,在 2013 年「邓丽君 60 追梦纪念演唱会」上,鲜少出席活动的王菲与偶像隔空对唱了这首《清平调》。
王菲演唱会原唱
这一次,我们让 Mureka 模拟王菲的音色,并在此基础上重新谱曲、演唱。
Mureka 生成的声线再现了王菲特有的空灵、通透,处理歌曲中的弱唱又模拟出王菲标志性的气声效果。咬字方面,Mureka 同样还原了王菲不咬死字头,让声音在口腔中自然流淌的唱法,尤其在尾音收放上,更是有股菲式慵懒感。
我们再来试试它的「音乐参考」功能。
所谓音乐参考,就是通过分析用户上传的音乐,Mureka 能够精准识别原曲的类型、节奏、配器和情绪,并据此生成具有相似风格的原创作品。
前段时间,中国网红「豪哥哥」改编印度神曲《Tunak Tunak Tun》(也就是那首著名的《我在东北玩泥巴》),创作出这首魔性十足的《刚买的飞机被打啦》。
视频来自博主「豪哥哥 - 魔性改歌」
这首歌一经发布就在全球社交媒体疯狂刷屏,甚至一度把印度网友搞破防,联名「上书」联合国。
我们也拿 Mureka 做了一版,曲风相当洗脑,要是口音咖喱味再浓点就好了。更有意思的是,Mureka 还能自动生成 MV,抽象画面配上黄色描边歌词,又土又上头。
此外,Mureka 还升级了歌曲描述、纯音乐生成等常规功能。
比如,我们输入李白的《将进酒》,再选择音乐风格「说唱金属,另类金属,说唱摇滚,男声」,Mureka 立马化身摇滚老炮,激情开唱。
或者通过文字 Prompt 直接生成免版权的 BGM:
提示词:回忆童年的温暖钢琴旋律
也可以上传参考音频,让模型创作出风格相近的纯音乐片段。
如果对生成的音乐不满意,Mureka V7 还提供音频编辑功能,可以局部编辑、延长歌曲、乐器分轨甚至裁剪音频,并支持 10 种语言的 AI 音乐创作。
自研音乐思维链「MusiCoT」再次进化
不到四个月的时间,Mureka V7 相较于上代 Mureka V6 的表现又提升了一大截,这源自昆仑万维对自研音乐生成专用思维链 —— MusiCoT 的持续优化。
我们知道,大语言模型的内容输出方式是「预测下一个 token」,这显然与音乐创作的过程不同。为此,昆仑万维在 Mureka 中引入了生成式 AI 领域流行的思维链(CoT)提示方法,并通过 V6 版本完成了首秀。
此次,Mureka V7 进一步优化了 MusiCoT(Analyzable Chain-of-Musical-Thought Prompting)技术,显著提升了模型生成结果的整体性与发声表现,具体包括以下三大方面的创新。
一是,先想结构后生成,符合人类创作逻辑。
MusiCoT 在输出音频 token 之前,会先让模型生成对音乐结构的全局规划,确定整体的段落、情绪、编排等布局。这就能让 AI 生成的作品具备清晰的结构。
二是,生成结构可解释、可控。
通过 CLAP(对比式语言 - 音频预训练模型),MusiCoT 的明确思维链让 AI 生成的音乐具有明确的可读性和可控性。用户可以输入任意长度的参考音频作为风格提示。
三是,主观 + 客观验证效果全面领先。
基于大量实验,MusiCoT 在主客观双重指标下均展现出了卓越的效果。无论是结构完整、旋律连贯还是整体音乐性均优于传统方法,在多项评测中表现达到行业顶流水准。
在 Mureka V7 上,MusiCoT 不仅在结构层面实现对音乐创作思维的拟合与对齐,更借助数据的进一步扩展、嵌入信息粒度的细化,完善了可控性与可扩展性。
得益于 MusiCoT 的升级和应用,Mureka 部分生成作品已经能够为音乐人提供更多创作灵感,并加速从灵感到成品的落地过程。
定制语音有了更好的国产选择
此次,除了更强、更拟人、更自然的音乐生成之外,昆仑万维还带来了一款音频模型 ——Mureka TTS V1。该模型支持的语音创作功能也已经上线官网。

与音乐生成强调旋律、和声、节奏、风格等音乐语言的表达不同,音频模型更关注对所有声音类型的通用表示与理解,包括语音、人声、环境音、音效等。Mureka TTS V1 的最大亮点是引入了 Voice Design 能力,可以通过文本输入想要的语音特征来获得对应的音色。
这意味着,不论是真实人物、虚拟人物还是配音角色都能够通过文本来控制,不用像过去一样只能通过预设音色库来实现音色克隆。相反,用户能够通过自然语言指令灵活定义声音的性别、年龄、情感状态、语气风格、表达节奏,达成真正个性化、场景化的语音合成体验。
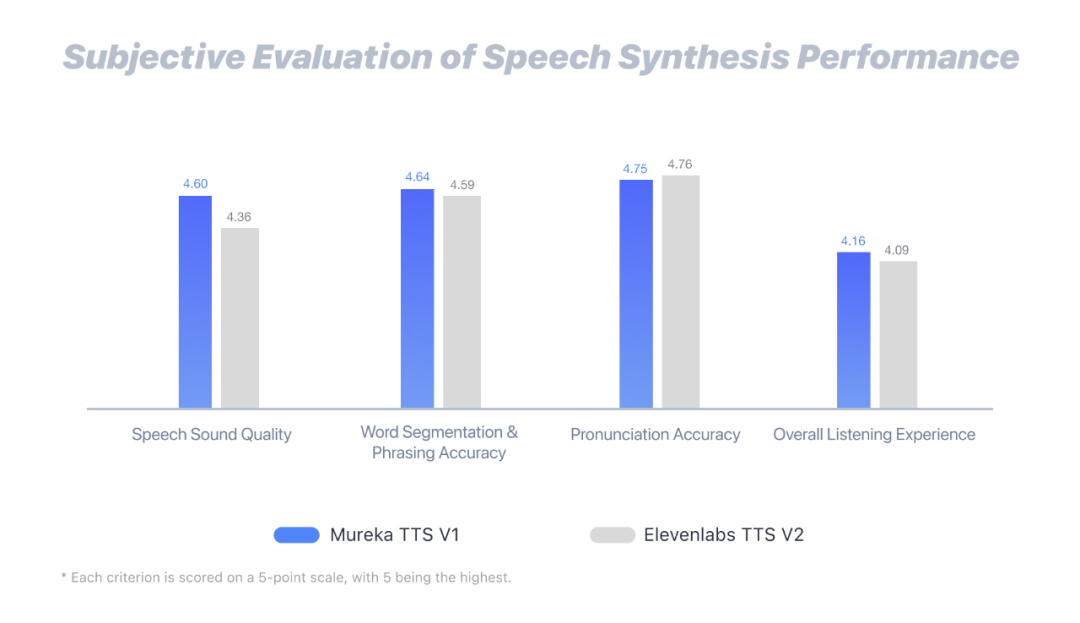
跑分结果显示,在与竞对 ElevenLabs TTS V2 的较量中,Mureka TTS V1 的语音质量、分词与语句节奏准确性以及整体听感体验均实现了超越,只在发音准确性方面略逊一筹。如此一来,昆仑万维在语音合成的多个核心维度上已具备行业领先优势,可以进一步满足更高阶的语音创作与交互场景的需求。
最终好不好,还是得看实际效果。
我们来听一段人声,「童音女声,12 岁左右,声音清脆悦耳,热情洋溢,语速略快但不慌乱。」
再来一个「男性新闻播音员,语音清晰且稳定,语调平稳、沉着,语速适中,语气冷静理性,情感中性且客观,音量适中,声音具有一定的厚重感,体现专业性与可信度」。
可以看到,Mureka TTS V1 从创意描述到声音输出实现了全流程生成,声音创造更加高效与自由,不仅大大拓展了语音生成的应用边界,也为内容创作与交互体验打开了想象空间。未来,该模型可以进一步在影视、游戏、广告等行业的配音场景大显身手。
写在最后
最近一段时间,随着 Scaling laws 放缓,模型规模扩展所带来的边际收益减弱,各家厂商卷基础大模型的步伐也开始放缓。相反,大模型的「价值兑现」与「商业化落地」正在加速推进中。
随之而来,一些垂直大模型成为新一轮技术博弈与产品竞速的焦点,如 AIGC 领域的视频大模型、音乐大模型等。大家都卯足了劲抢占规模化落地的红利,率先打通从技术到产品的转化路径,占据内容创作、营销、娱乐等高频应用场景的生态入口。
这一趋势与昆仑万维长久以来的战略天然契合。在「实现通用人工智能,让每个人能够更好地表达自我」的使命驱使下,该公司形成了「AI 前沿基础研究 —— 基座模型 —— AI 矩阵产品 / 应用」的全产业链,持续发力 AIGC 创作领域,并推出覆盖视频、音乐、Agent 等多个方向的创新型产品。
其中自 2024 年 4 月亮相以来,Mureka 作为「会思考」音乐模型的名头越打越响。今年,Mureka 已经迎来了两次大版本更新,上个版本 V6 直到最近仍被很多国外网友「安利」。


甚至从 3 月底到现在,Mureka 的新增用户就接近 300 万。显然,昆仑万维的音乐大模型获得了用户的高度认可,并正在引领音乐创作方式的变革。
未来,随着模型能力的持续增强与创作门槛的进一步降低,AI 有望演变成为音乐创作的核心驱动力。同时,音乐创作也将继续打破专业壁垒,走向全民表达。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com
 扫码添加微信
扫码添加微信

- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







