


【AI加油站】AI面试专题二十二:消息队列Kafka的面试题资料(附PDF下载)
- 2025-07-21 08:00:00

基本信息
Kafka:一个分布式发布-订阅消息系统和强大的队列,能处理大量数据,支持离线和在线消息消费,消息保留在磁盘上并在群集内复制以防止丢失,构建在ZooKeeper同步服务之上,与Apache Storm和Spark集成用于实时流式数据分析。
依赖Zookeeper:用于协调和管理Kafka集群。
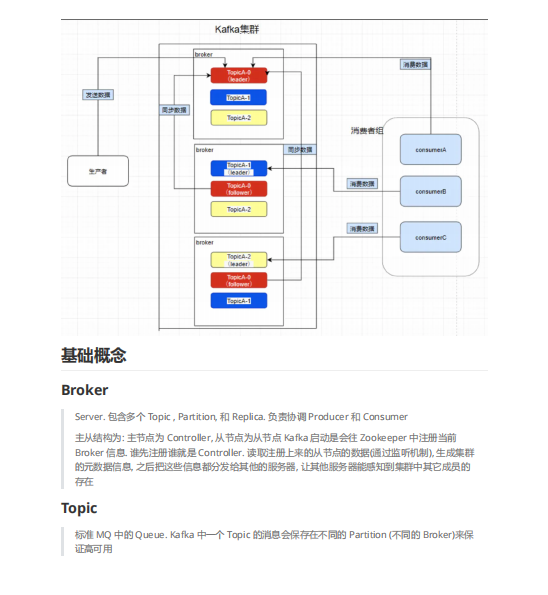
架构
Broker:服务器,包含多个Topic、Partition和Replica,负责协调Producer和Consumer。启动时向Zookeeper注册信息,第一个注册的成为Controller,读取从节点数据生成集群元数据并分发给其他服务器。
Topic:类似于标准MQ中的Queue,一个Topic的消息保存在不同Partition(不同Broker)以保证高可用。
Partition(分区):将标准MQ的Queue消息拆分,实现高可用。Producer发送的Message根据key和partition数进行hash后投递。一个分区只能被同一个Consumer Group中的一个Consumer消费,分区内消费有序。
Replica(备份):每个Partition的备份,数量小于等于Broker数量。Leader是Replica领导节点,Producer写数据只往Leader写,Consumer也从Leader读;Follower用于复制Leader数据,采用pull模式。
ISR(In-Sync Replica):Leader维护的与Leader基本保持同步的Replica列表,每个Partition都有ISR,由Leader动态维护。若Follower落后太多或超时未发起复制请求,Leader将其从ISR移除。当ISR中所有Replica向Leader发送ACK时,Leader才commit。
消息丢失与重复消费:Leader宕机后,从ISR选数据最新的Follower当Leader;若ISR全宕机,选第一个回复的Replica当Leader,可能丢失或重复消费消息。相关参数有
replica.lag.time.max.ms(Follower未发起fetch请求的时间,超过则被移出ISR)、replica.lag.max.messages(复制消息相差数量,超过则移出ISR)、min.insync.replicas(保证ISR中最少Replica数量)。水印备份机制:LEO(日志末端位移)记录副本底层日志文件中下一条消息位移值,Leader保存自己和remote LEO值;HW(高水印值)不大于LEO,小于HW的消息被认为已提交或备份,对消费者可见。
消息与数据交互
Message:标准MQ中的消息。
Producer:发送方,使用push模式发送给Broker。数据一致性保证方面,
request.required.acks参数可设置为0(异步,可能丢失或重发)、1(Leader接收后ack,丢失概率小)、-1(所有Follower同步成功后ack,不会丢失消息)。Consumer:消费方,使用pull模式,默认100ms拉一次。消费的是Partition的数据,需手动确认ack避免消息丢失,消费端需幂等处理避免消息重复。Consumer Group可消费一个Topic,保证同一条Message不被不同Consumer消费,但Consumer数量不能超过Partition数量。
分片与分配
分片规则:Kafka分配Replica的算法有RangeAssignor和RoundRobinAssignor,默认RangeAssignor,按一定规则将Partition分配到不同Broker上。
Rebalance(重平衡):Consumer Group下所有Consumer达成一致分配订阅Topic分区的协议。触发条件包括组成员个数变化、订阅Topic的Consumer Group个数变化、Topic分区数变化等。Rebalance过程分为Join和Sync两步,Join是成员加入组并选Leader,Sync是Leader分配消费方案并通知各Consumer。
性能优化
分区原因:避免加锁影响性能,以Partition为分界支持并发,类似Java 1.7的ConcurrentHashMap桶设计。
顺序写:磁盘顺序写性能优于内存随机写,Kafka利用这一点提高性能。
批发送:减少网络传输Overhead,提高写磁盘效率,批量发送单位默认16384Bytes,满足条件即发送。
数据压缩:重复数据多时压缩效果好,Kafka将整个Batch数据压缩,Broker接收后直接持久化,Consumer解压缩,提高传输效率。
Page Cache & MMap:Kafka利用Page Cache和MMap减少文件拷贝和上下文切换,提高性能。写数据时直接写入Page Cache,消费者拉数据也经过Page Cache,若写速率和消费速率相当,则整个过程为内存操作。Kafka不自己管理缓存,因JVM对象存储有overhead,且受GC影响,程序崩溃后缓存数据会丢失。


本书免费下载地址
关注微信公众号“人工智能产业链union”回复关键字“AI面试22”获取下载地址。

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







