讲透一个强大算法模型,LightGBM !!
- 2025-06-30 14:26:00
哈喽,大家好~
今儿再来和大家聊聊LightGBM。
LightGBM,全名是 Light Gradient Boosting Machine,中文可以理解为:轻量级梯度提升模型。
简单说:它是一个 帮你用数据建模型、做预测的聪明工具,比如预测房价、客户是否流失、哪个用户可能点广告等等。
比如你是一个老师,要给班里同学评分,但你不是一个人评分,而是请了一群“助教”,每个助教都很笨、只会看一个角度,比如:
有的只看语文成绩 有的只看出勤率 有的只看上课发言情况
他们每个人都给出一个不完美的评分。
于是你这样安排:
让一个助教先评,其他助教看这个评得不好,就来补救它评错的地方。
每个助教后面都在努力“修正”前一个助教的错误。最后一群助教的评分加在一起,就变得很聪明!
这就是 LightGBM 背后的思想:“集体补错、逐步改进”。
为什么叫 Light ?
“Light” 是说它 轻快、快速、节省内存。为啥快?因为它用了两大招:
招式一:先分叶子,不是按层分
普通决策树(比如 XGBoost)是“从上往下一层层分”。
LightGBM 说:我不管层,我挑“信息最多”的叶子节点来分裂,也就是“叶子优先”。
这样做效率更高,长得更深的地方可以优先优化。
招式二:聪明地选要看的数据(Histogram 技术)
它不会去看所有的值,而是先把特征值分成“区间”(比如分成10个桶),这样处理起来更快,而且更省内存。
举个例子(预测房价)
有一堆数据,比如:
你想训练模型,输入面积、楼层、地铁,来预测房价。
LightGBM 会这样做:
把这些特征变成它喜欢的数字样子。 用它的“助教们”(很多棵树)一个个来试图“猜”房价。 前面的树猜不准,后面的树就来“修正”。 所有树的猜测加起来,就是预测的结果。
结果:它可以做到比你单纯用一棵树猜房价要准很多!
总的来说,LightGBM 是一个聪明、快速、节省资源的“树模型堆叠工具”,擅长通过一群笨树不断纠错,一点点把预测做得越来越准。
深入原理
基本思想:Boosting 的迭代优化框架
LightGBM 是 Gradient Boosting Decision Tree(GBDT) 的一种高效实现。GBDT 是一个 迭代模型,每一步都在拟合残差(也就是前一轮的误差)。
我们目标是学一个函数 ,去拟合目标变量 :
其中, 是第 棵树。
每一步,我们都最小化一个损失函数 。常见的是平方误差或对数损失:
一阶与二阶导数(XGBoost/LightGBM 特有)
使用泰勒展开到二阶(即用导数近似):
其中:
是一阶导数(梯度) 是二阶导数(Hessian)
LightGBM 会基于这个公式建树,使损失函数下降最多。
建树时怎么选分裂点?(信息增益)
每次节点分裂,会计算 增益(Gain):
:左右子节点的一阶导数之和 :左右子节点的二阶导数之和 :正则化项 :控制是否分裂的阈值
LightGBM 会选增益最大的特征进行分裂。
完整案例
我们现在构造一个案例来模拟:客户是否会购买产品(分类问题)
使用虚拟数据(make_classification 生成),使用 LightGBM 模型~
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.metrics import confusion_matrix, roc_curve, auc
import matplotlib.pyplot as plt
import seaborn as sns
import shap
np.random.seed(42)
# 创建模拟数据
X, y = make_classification(n_samples=1000,
n_features=10,
n_informative=6,
n_redundant=2,
n_clusters_per_class=2,
weights=[0.6, 0.4],
flip_y=0.02)
feature_names = [f'feature_{i}' for i in range(X.shape[1])]
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y
# 分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
df[feature_names], df['target'], test_size=0.3, random_state=42)
# LightGBM 模型训练
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test)
params = {
'objective': 'binary',
'metric': 'binary_logloss',
'learning_rate': 0.05,
'verbose': -1
}
model = lgb.train(params, train_data, valid_sets=[test_data], num_boost_round=100, early_stopping_rounds=10, verbose_eval=False)
# 特征重要性图
lgb.plot_importance(model, max_num_features=10, importance_type='gain', figsize=(10,6), color='tomato')
plt.title('特征重要性(按信息增益)')
plt.tight_layout()
plt.show()
# 混淆矩阵 + 热力图
y_pred_proba = model.predict(X_test)
y_pred = (y_pred_proba >= 0.5).astype(int)
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt="d", cmap="YlGnBu")
plt.title("混淆矩阵")
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.show()
# ROC 曲线
fpr, tpr, _ = roc_curve(y_test, y_pred_proba)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8,6))
plt.plot(fpr, tpr, color='orange', label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC 曲线')
plt.legend()
plt.show()
# SHAP 值图(模型解释)
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
shap.summary_plot(shap_values, X_test, feature_names=feature_names, plot_type='bar') # 汇总条形图
shap.summary_plot(shap_values, X_test, feature_names=feature_names) # 蜂群图
# 可视化散点图:模型输出 vs 实际
plt.figure(figsize=(8,6))
plt.scatter(np.arange(len(y_test)), y_pred_proba, c=y_test, cmap='coolwarm', alpha=0.7)
plt.axhline(0.5, color='gray', linestyle='--')
plt.title("分类预测分数分布(颜色=实际标签)")
plt.ylabel("预测概率")
plt.xlabel("样本编号")
plt.show()
1. 特征重要性图(Feature Importance Plot)
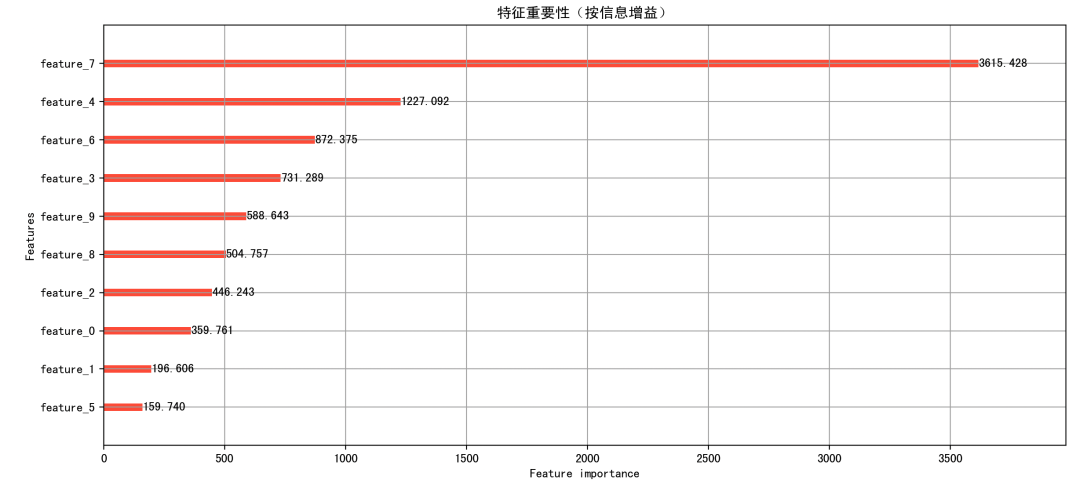
lgb.plot_importance 输出的柱状图:通常重要性越高的特征,越值得在业务上关注。
比如:想预测客户是否购买,发现 feature_3 是最重要的特征,可能说明这是一个关键指标,比如收入或浏览时间等。
2. 混淆矩阵(Confusion Matrix + 热力图)
4 格热力图,显示 TP, TN, FP, FN 的数目,展示模型的分类结果与实际情况的对比,分类准确性一目了然。

FN 多:模型漏掉了太多正类(比如漏判买东西的客户) FP 多:模型误判了太多负类(比如以为客户会买,结果没买)
3. ROC 曲线
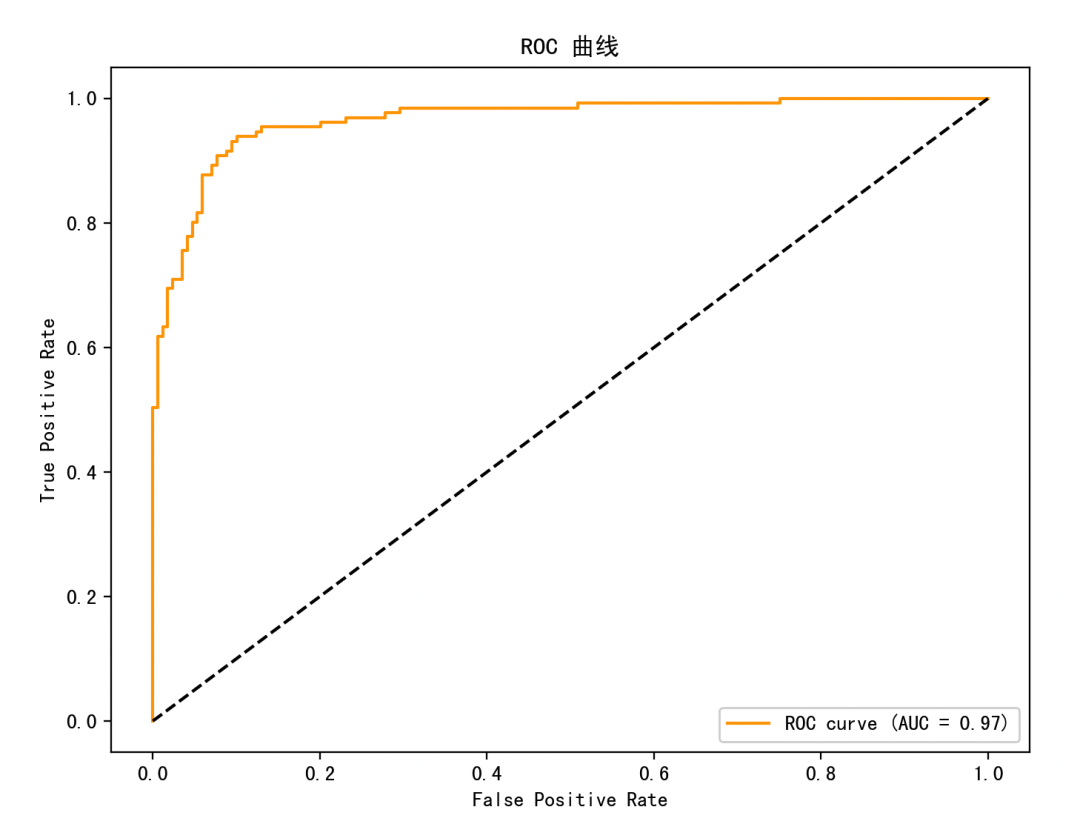
X 轴是假阳性率 (FPR),Y 轴是真阳性率 (TPR),曲线越靠左上角越好,衡量二分类模型在各种判断阈值下的总体表现。AUC(面积) 是最核心指标,越接近 1 越好,表示模型有强分类能力。
4. SHAP 图(模型解释图)
SHAP 条形图 → 各特征对预测影响的平均大小。


SHAP 是目前最流行的可解释模型分析方法。告诉咱们:“这个模型是为什么做出这个判断的”。比如,feature_2 高了 → 更倾向正类;feature_4 低了 → 更倾向负类。
5. 分类概率散点图
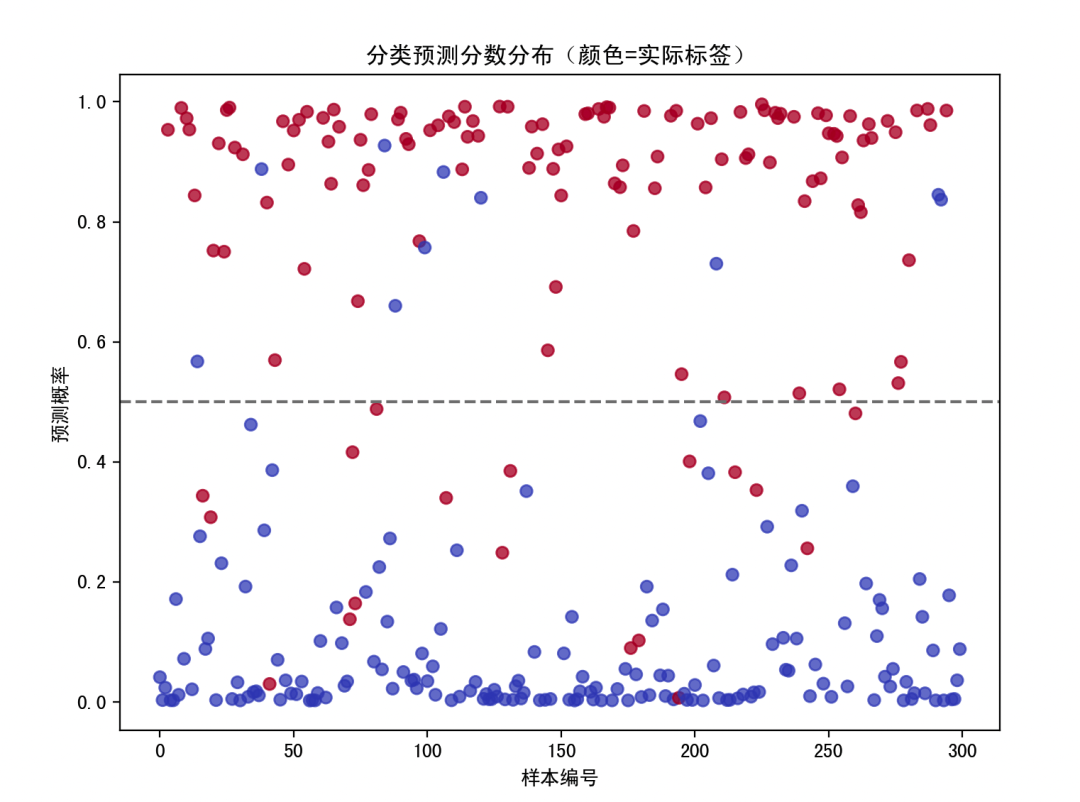
每个测试样本的预测概率(Y 轴),颜色表示真实标签。蓝色点(正类)应该出现在上方(高概率区),红色点(负类)应该出现在下方(低概率区)。
LightGBM 是一种高效的梯度提升树模型,用于处理结构化数据的预测问题。 它通过多棵决策树迭代优化残差,每步使用一阶和二阶导数来精确建树。
最后


 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊