


体系结构顶会ISCA'25放榜:中国作者斩获最佳论文,拿下25%录用!附超全总结
- 2025-07-31 13:25:47

新智元报道
新智元报道
【新智元导读】香港科技大学谢源教授领导的「赛马会未来先进计算技术创科实验室」对刚刚召开的ISCA会议进行了全面总结,涵盖历史发展和技术细节,总结出了体系结构领域有潜力的研究方向!
ISCA(The International Symposium on Computer Architecture)是计算机体系结构领域的顶级会议。第52届ISCA于2025年6月21日至25日在日本东京早稻田大学举行。
今年的ISCA共收到了570篇论文投稿,最终录取132篇,录用率为23%。录取文章涵盖微架构设计、机器学习、领域定制加速器、量子计算、存算一体等众多话题。
香港科技大学赛马会未来先进计算技术创科实验室(JC STEM Lab of Future Advanced Computing Technology)汇总了2016年以来ISCA上各个话题文章的论文占比。

通用微架构相关的ISCA文章数量占比

加速器相关的ISCA文章数量占比

存储器与存算一体相关的文章数量占比

量子计算相关的文章数量占比
传统的通用CPU/GPU微架构、Cache及架构建模仿真的相关研究依然占据较高比重,但其占比自2016年以来趋于平稳并略有下滑。
与之形成鲜明对比的是,加速器(Accelerator)和机器学习(ML/AI)相关研究持续攀升,成为增长最快的领域,稀疏计算、数据流与可重构加速器、量化等软硬件协同优化技术是其中最具代表性的子领域。ISCA 2025中加速器的论文占比超过50%,机器学习相关文章占比超40%。纵向对比显示,过去十年间机器学习在ISCA的占比稳定维持在20%-30%区间。
其中,大模型毫无疑问是当下最热门的应用方向,面向大模型的架构与软硬件协同优化文章数量增长迅猛,ISCA 2025超过20%的文章关注大模型加速。除了AI算法外,图形渲染、隐私安全与数据加密等同样是ISCA近年来关注的热门应用方向。
此外,存算一体和量子计算两个领域的文章数量在近年来保持较为平稳的增长趋势。
值得一提的是,基于非易失器件的存算一体文章数量在近几年呈下降趋势,而内存级Near-Memory-Computing和外存级In-Storage-Processing的文章占比相对提升,Hybrid Bonding等先进封装技术的出现推动越来越多的研究者探索基于3D IC的存算一体架构设计。
本文作者为朱振华,徐策羽,王邦彦,刘时宜,杨朝辉,范心,余江南,王鸿懿,宋如意,刘奇,夏一然(以上排名不分先后)。

ISCA自1973年创办以来仅有三次在东亚地区举办,分别为2008年北京、2016年首尔,以及2025年东京。从地域分布来看,每一次在东亚地区举办的ISCA会议都极大提升了该地区学界与工业界的参与度,也成为观察本地区研究力量崛起的历史节点。
在2008年北京举办的ISCA上,仅有一篇国内单位的论文入选:来自复旦大学的「From Speculation to Security: Practical and Efficient Information Flow Tracking Using Speculative Hardware」。
该工作针对动态信息流追踪(Dynamic Information Flow Tracking, 又称 Taint Tracking)在缺乏硬件支持下效率低下的问题,首次提出利用处理器推测执行中的延迟异常机制来模拟taint状态,构建出一套无需专用硬件支持、低开销、适配灵活的追踪框架,该文章代表了国内团队在体系结构(硬件安全)领域的早期探索。
论文第一作者陈海波,彼时在复旦大学攻读博士学位。如今他已是上海交通大学特聘教授、国家杰出青年基金获得者、IEEE Fellow,成为分布式系统与可信计算领域的全球权威学者。其成长轨迹恰是中国系统架构人才从本土培养到国际引领的缩影。
2016年首尔举办的ISCA会议,中国团队共有两篇论文被接收。其中,来自中国科学院计算技术研究所的「Cambricon: An Instruction Set Architecture for Neural Networks」率先提出了面向神经网络的指令集架构,打破了早期AI加速器对「特定模型+硬编码控制」的依赖,被广泛视为后续AI加速器设计潮流的重要奠基之作。
另一篇「Power Attack Defense: Securing Battery-Backed Data Centers」来自上海交通大学,关注于电池供电数据中心的安全性问题,体现了中国高校在系统安全与数据中心可靠性领域的深入探索与贡献。
到了2025年东京举办的ISCA,中国团队的参与度实现飞跃:在全部132篇录用论文中,有34篇来自国内团队,论文内容涵盖微架构优化、AI加速器、存储系统、量子计算等多个热点方向。这不仅是投稿数量上的增长,更意味着在体系结构各核心议题上,中国团队正在从「跟跑」迈向「并跑」甚至「领跑」。
值得一提的是,来自北京大学孙广宇教授团队、上海交通大学张宸教授团队、香港科技大学谢源教授团队、东南大学司鑫教授团队及阿里巴巴达摩院的合作研究成果「H2-LLM: Hardware-Dataflow Co-Exploration for Heterogeneous Hybrid-Bonding-based Low-Batch LLM Inference」获会议最佳论文奖,这也是ISCA 52年历史上首篇来自中国团队的ISCA会议最佳论文,至此,国内团队集齐计算机架构领域四大(ISCA, MICRO, HPCA, ASPLOS)最佳论文。
从2008年的孤篇论文,到2025年高占比、多方向、出佳作,三次在东亚召开的会议见证了中国体系结构研究在全球舞台上的成长轨迹,也反映出国内在计算架构领域「从可见到可为」的历史跃迁。
上述趋势同样可以从ISCA名人堂(Hall of Fame)https://pages.cs.wisc.edu/~arch/www/iscabibhall.html的入选名录里加以印证。ISCA名人堂收录了在ISCA会议上累积发表文章不少于8篇的研究者,由体系结构领域著名学者威斯康辛大学的Mark D. Hill和Gurindar S. Sohi于1995年创建,旨在表彰在ISCA会议上做出重要贡献的杰出研究者。
该榜单目前更新至ISCA 2024。在ISCA名人堂创立后的相当长时间里,上榜的华人学者数量稀少,仅有UIUC胡文美教授,香港科技大学谢源教授等为数不多的几位华人学者入选,而在中国大陆(含香港、澳门、台湾)本土工作的学者几乎无人入选,反映出早期国内在体系结构顶会上的论文产出相对有限。
然而近10年来情况开始改观,中国研究团队在ISCA上实现了一系列突破,在2023年清华大学魏少军教授和刘雷波教授成为首批入选名人堂的大陆学者。此外,近年来也有多位ISCA名人堂学者从海外归来,比如香港科技大学的谢源教授(截止ISCA 2025共发表23篇ISCA论文)和清华大学的钱学海教授,他们进一步推动了中国在体系结构研究的崛起。
除了清华大学外,中国其他高校和中科院也在近年逐步发力,相信我们可以在ISCA 2025更新后的名人堂中看到更多中国学者。

ISCA 2025的最佳论文奖评选结果充分体现了当今计算机体系结构领域新兴与传统并重、承前启后的发展态势。
两篇获奖论文从不同维度展现了该领域的创新活力:既有运用现代理论工具重新审视经典核心问题的深度探索,更有紧跟时代脉搏、面向AI时代新应用需求的前瞻性研究。


来自剑桥大学、爱丁堡大学、奥胡斯大学等顶尖学术机构的研究团队凭借论文「Precise exceptions in relaxed architectures」荣获最佳论文奖。该研究针对现代高性能处理器架构中的一个核心挑战——如何在松散内存模型环境中准确定义和处理异常。
传统的异常精确性定义基于60多年前的顺序执行模型假设,然而现代架构如Arm-A具有程序员可观察的松散内存行为,这使得传统定义变得不再适用。
研究团队深入探索了异常在松散内存环境中的行为特征,包括乱序执行、推测执行以及跨异常边界的数据转发等现象,并开发了针对Arm-A架构的精确异常公理化模型。该工作不仅澄清了在松散内存设置中讨论异常所需的概念和术语,还探索了软件生成中断的松散语义,为Linux内核的RCU同步机制和Microsoft Verona编程语言运行时等复杂系统软件提供了理论基础。
这项研究体现了「理论深化实践」的研究精神,为现代处理器架构规范的明确化定义做出了重要贡献。


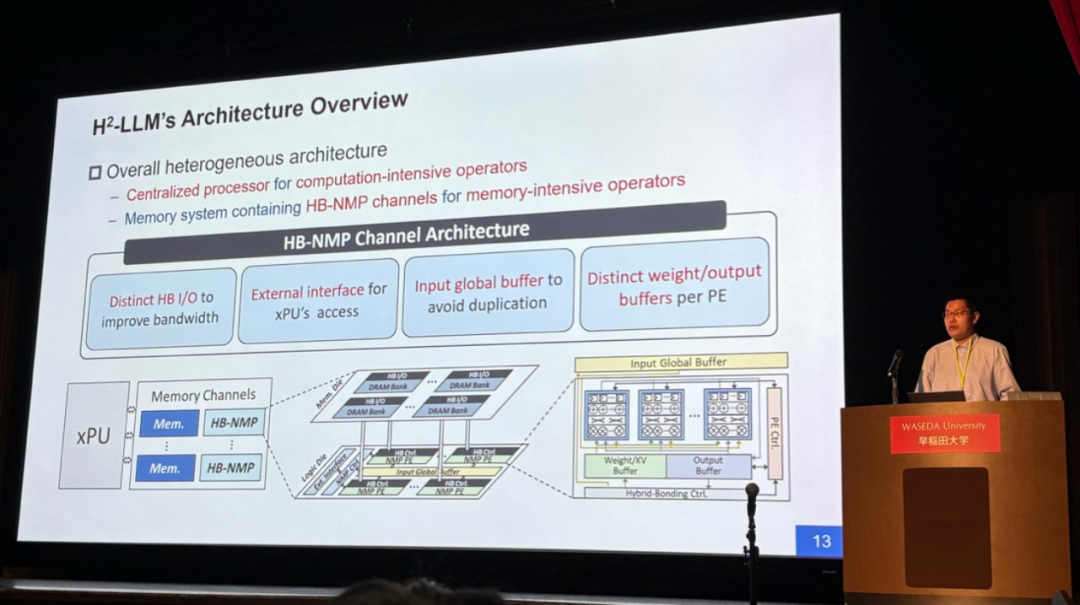
另一篇获奖论文则展现了体系结构领域对人工智能时代新挑战的积极回应。来自北京大学孙广宇教授团队、上海交通大学张宸教授团队、香港科技大学谢源教授团队、东南大学司鑫教授团队及阿里巴巴达摩院的合作研究成果「H2-LLM: Hardware-Dataflow Co-Exploration for Heterogeneous Hybrid-Bonding-based Low-Batch LLM Inference」同样荣获最佳论文奖。
该研究针对边缘侧大语言模型推理面临的关键技术挑战,创新性地提出了基于混合键合(Hybrid Bonding)技术的异构加速架构H2-LLM。
针对现有DRAM近存计算架构算力供给不足的问题,研究团队通过提出通用近存计算架构模板,抽象设计空间以协调工艺中算力与带宽的权衡,并采用「以数据为中心"的数据流抽象优化异构硬件资源利用,实现了计算密集型与访存密集型算子的协同加速。
实验结果显示,相较于基线DRAM近存架构,H2-LLM在LLM推理的预填充(Prefill)和解码(Decoding)阶段实现了2.72倍的性能提升与1.48倍的能效优化,体现了「应用驱动架构创新」的发展理念。

从CNN视觉模型的兴起以来,模型规模的指数级增长与日新月异的模型结构不断的为体系结构领域注入着新的活力重塑体系结构研究范式。2016年学者「ISCA的C已成为CNN的C」的论断,在Transformer时代得到更深刻的印证——2025年的今天,「ISCA的A正演进为AI的A」已成为学界共识。ISCA 2025创下三项里程碑:
录用论文135篇,创历史新高;
大模型加速器首获最佳论文奖;
首次设立LLM专题Session。

随着模型参数规模从小到大的持续扩展,AI系统面临的挑战也从单一节点的计算效率演变为涵盖计算、通信与存储的全局优化问题。
在硬件与系统微架构层面,包括模型量化支持、近存计算在内的技术成为提升能效比和计算密度的核心手段,直接影响单节点的推理与训练效率。
而在更大尺度的系统宏架构层面,则需关注超节点的组网设计、高效的系统通信算法以及资源池化能力,以实现跨节点、跨集群的弹性扩展与高吞吐低延迟的协同计算。
从微观到宏观,AI系统的构建正演变为一场跨越软硬件、融合算法与架构的系统性工程挑战。
在相关文章中,来自香港科技大学(广州)黄嘉逸教授团队的Chimera通过系统性地分析通信模式,识别出在并行切换时的通信冗余,提出了一种通用且兼容各种并行组合的优化方法,该文章获ISCA 2025 Distinguished Artifact Award奖项。
Chimera将相邻的通信操作符进行重排序并融合成更高效的通信原语。该方法不仅减少了通信总量,还避免了中间状态的冗余同步,显著提升了通信带宽和整体训练性能。
此外,Chimera兼容现有优化方法(如核融合和调度优化),为构建更高效的大模型训练系统提供了新的基础支持。

随着晶体管的微缩逐步到达其物理极限,以及先进芯片的尺寸达到光罩尺寸(reticle size),现在越来越难以通过继续传统的缩小晶体管尺寸、扩大芯片面积的方式提升单芯片集成度;另外一方面,现在的芯片性能在越来越多情况下被内存、通信带宽而非计算所限制,而这也是单纯缩小晶体管尺寸所难以解决的。
许多新兴制造工艺或许正是解决以上问题的一剂良药。从3D集成工艺到非易失存储器件再到芯粒(chiplet)技术,制造工艺上的演进能够带来集成度、内存带宽等技术指标上的颠覆性提升,也不断刺激着全芯片架构的不断涌现。
本次ISCA会议上,我们主要看到了由三种新型工艺驱动的架构设计讨论:晶圆级计算 (wafer-scale computing)、混合键合 (hybrid bonding)、光计算 (photonic computing)。
晶圆级计算无疑是本次会议的一个焦点所在,ISCA 2025共接收了4篇文章。晶圆级计算是一种将整个硅晶圆作为单一超大规模计算系统的技术架构。其核心理念是不再将晶圆切割成小块芯片,而是直接在完整晶圆上构建计算阵列,通过片上互连网络将数千个处理核心连接起来,形成一个巨型的并行计算平台。
相比传统GPU集群,这种架构可以提供约50倍的晶体管数量和6倍的片间带宽,同时通过短距离片上互连(<5mm)替代传统PCB走线(50-100mm),显著降低了通信延迟和功耗。
此外,晶圆级系统消除了外部NVLink交换机、光互连等组件需求,大幅减少了系统复杂度和成本,同时支持近乎完美的线性性能扩展,可实现数百万AI优化计算核心的协同工作。
然而,晶圆级计算芯片也面临着一系列设计挑战。晶圆级计算的主要挑战在于如何在有限的晶圆面积约束下平衡计算、存储和通信资源的分配。由于晶圆总面积固定(约70,000mm²),增加DRAM容量会占用更多面积并消耗更多片间互连接口,导致可用计算资源和片间通信带宽的减少。
同时,系统还面临互连距离限制(超过50mm会导致误码率增加10⁸倍)、封装可靠性约束、以及复杂的多层级设计空间优化问题。
此外,缺乏细粒度的参数化建模框架和综合评估系统,使得在设计阶段难以实现计算架构和硬件架构的协同优化,这些都成为实现最优集成密度和性能的关键瓶颈。
对于这些问题,清华大学尹首一教授、胡杨教授团队发表的「Cramming a Data Center into One Cabinet, a Co-Exploration of Computing and Hardware Architecture of Waferscale Chip」一文针对晶圆级芯片资源分配这一关键问题,通过计算与硬件架构的协同探索,有效解决了在有限晶圆面积下计算、存储、通信资源的最优权衡难题,并引入垂直集成架构约束实现了系统级优化。

晶圆级芯片架构
另一个晶圆级架构的代表性工作,同样来自清华大学尹首一教授、胡杨教授团队的WSC-LLM则专门聚焦于AI时代最重要的大语言模型(LLM)工作负载,通过架构与调度的协同设计,创新性地解决了LLM推理中预填充和解码阶段动态资源需求不匹配的问题,并提出了高效的分布式内存管理策略。这两项工作都体现了软硬件协同优化的设计理念,为突破传统多卡集群的内存和通信瓶颈、充分释放晶圆级计算潜力提供了重要的技术路径,代表了在新工艺约束下寻求最优系统性能的前沿探索。

面向LLM的晶圆级架构资源分配与管理
混合键合是一种先进的键合工艺,用于在3D IC的制造中形成上下相邻的两晶片间的物理及电路连接。相较于原先的微凸点键合(micro-bump bonding)工艺能够带来3D IC中垂直互联密度和带宽上数量级的提升。这一技术突破为解决长期困扰计算系统的「存储墙」问题开辟了新的路径。
本次会议最佳论文奖的H²-LLM一文充分利用混合键合带来的高垂直互联密度优势,通过DRAM die与逻辑die的3D异构集成,解决了边缘LLM推理中计算能力与内存带宽的权衡难题,相比传统片内近存计算方案实现了2.72倍的性能提升。这篇论文也荣获本届ISCA会议最佳论文奖,将在本文后续部分中详细介绍。
光计算作为突破传统电子计算瓶颈的新兴技术,具有独特的优势与挑战。其核心优势在于光互连不受焦耳热、RF串扰和电容等传统电子器件的能效限制,能够实现极高的带宽密度,并支持在每个交叉点同时进行数十亿次乘累加(MAC)操作。
然而,现有光计算工作往往局限于物理层面的概念验证,缺乏完整的系统级架构支持,特别是在内存系统设计、通用ML操作支持等方面存在显著不足。
美国匹兹堡大学Jun Yang教授团队发表的「LightML: A Photonic Accelerator for Efficient General Purpose Machine Learning」提出了首个系统级光子交叉阵列架构,通过创新的内存和缓冲设计实现了超过80%的光子交叉阵列利用率。该工作巧妙利用相位调制器和傅里叶级数实现非线性函数计算,并通过电路级设计高效支持矩阵转置、批量归一化、ReLU等关键ML操作。LightML实现了325 TOP/s计算性能,功耗仅3W,相比GPU获得13.6倍能效提升,为解决AI时代「算力墙」问题提供了全新技术路径。
晶圆级计算、混合键合和光计算这三种新兴制造工艺代表了在摩尔定律逐步放缓背景下计算架构创新的重要方向。
它们分别从超大规模集成、3D异构集成和新型物理计算原理三个维度突破了传统电子计算的根本限制,为解决当前芯片设计中面临的「存储墙」、「通信墙」和「功耗墙」等关键瓶颈提供了颠覆性的解决方案。
本届ISCA会议上相关论文的集中涌现,不仅展现了学术界对这些前沿技术的高度关注,更预示着计算架构正在从传统的工艺驱动模式向工艺与架构深度协同优化的新范式转变。这种转变将为AI时代日益增长的算力需求提供更加高效、可持续的技术支撑,推动整个计算产业进入一个全新的发展阶段。

在ISCA 2025中,一共有5个Session与存储系统相关,内容涵盖前沿存储技术探索、外存系统优化、存算一体与存储加速器以及存储系统安全性研究。基于ISCA 2025的相关文章,我们将体系结构视角下的存储系统发展总结为如下三个重要趋势。

如何面向实际任务负载,设计「快速读写」的存储系统,是体系结构领域经久不衰的重要话题。
在ISCA 2025中,「应用驱动」成为回答这一问题的关键——结合应用特征进行软硬件协同优化,降低冗余访存量,设计专用存算架构,充分挖掘存储器内部带宽。相关文章主要关注检索增强生成(Retrieval-augmented generation, RAG)、数据库(Database)、图神经网络(Graph Neural Network, GNN)、生物信息学处理等应用场景。
其中,RAG与近邻搜索共有5篇文章入选存储系统的相关session,成为这一方向最热门的话题。
RAG是一种将外部检索到的相关信息动态融入生成任务中的技术,先通过向量检索模块从外部知识库中获取相关信息,再将检索结果作为附加上下文输入到生成模型中,以提升生成的准确性与一致性。
从硬件架构的角度,RAG中的检索任务具有存储需求高、计算相对简单的特征,因此,将计算任务「下放」到内存与硬盘里去执行,利用Processing-In-Memory与In-Storage-Computing的思想对存储系统进行计算功能的扩展,可以有效缓解CPU/GPU在信息检索过程中的数据传输压力。
面向检索任务的专用硬件架构曾是体系结构领域的重要研究话题,如MICRO'19的TensorDIMM、ISCA'20的RecNMP和MICRO'23的DF-GAS,这些架构普遍关注于基于检索任务的推荐系统优化。
在大模型越来越强的时代背景下,「信息检索」的应用场景也从经典的推荐系统任务,扩展到了检索生成一体化。
在一些工作负载下,检索召回的时间可占端到端时间的60%,也使加速RAG中的检索任务变得愈发重要,今年ISCA的相关论文可以被称为检索任务的「文艺复兴」。

RAG中不同计算阶段的延时占比。其中,Llama2-34B运行在A100 GPU上,其他组件运行在Intel Xeon CPU上。[Ref: In-Storage Acceleration of Retrieval Augmented Generation as a Service]
ANSMET,DReX与HeterRAG三篇文章关注在内存(Memory)层级的近存储检索架构设计,旨在通过近存储计算单元,充分挖掘DRAM的内部带宽,降低数据搬运的额外开销。
其中,清华大学高鸣宇教授团队的ANSMET与美国康奈尔大学Mohammad Alian教授团队的DReX均采用了软硬件协同优化的思想,通过「基于距离下界的提前早停」和「基于符号一致性的向量过滤」等方法,降低存储访问量与冗余计算量。
华中科技大学金海教授、廖小飞教授团队的HeterRAG在检索之外更进一步,设计了基于异构DRAM的检索生成一体化架构,将检索任务交给高容量、低成本的DIMM-PIM,而生成任务则交给高带宽的HBM-PIM,并通过局部性感知的调度优化与细粒度并行,实现端到端的带宽–容量均衡与能效最大化。

HeterRAG:(左)检索部分(右)生成部分
苏黎世联邦理工学院Onur Mutlu教授团队设计的REIS与加州大学圣地亚哥分校Hadi Esmaeilzadeh教授团队的RAGX两篇文章侧重于在外存(Storage)层级支持检索与嵌入计算,通过利用SSD/Flash的内部并行与带宽,显著减少主机–外存之间的数据搬运延迟。
REIS的特点在于保持现有SSD硬件不变,充分利用现有硬件单元和存储空间提高近似近邻搜索效率。REIS利用In-Storage-Embedded-Core以及SSD控制器支持倒排文件(Inverted File)的相似性计算与查找,优化嵌入表信息在SSD内的数据布局,并使用NAND Flash中保留的Out-of-Band(OOB)区域存储额外的地址等信息。
与之对应的,RAGX在SSD内部增加了可编程加速器,一方面以脉动阵列的模式支持基于小规模语言模型的查询嵌入(query embedding),另一方面以向量模式可以在检索阶段直接从NAND阵列中读取嵌入表。
除了支持嵌入计算外,RAGX实现了多种检索算法与数据结构的统一支持,包括HNSW与倒排索引等。

存算一体架构旨在让计算发生在数据存储的位置,从而降低存储器和处理器之间的数据搬运,打破冯·诺依曼架构的存储墙瓶颈。存算一体的设计思想可以追溯到二十世纪七十年代的Logic-in-Memory(LiM),受限于技术成熟度较低和应用需求不明确等问题,LiM未能实际落地应用。
近十年来,得益于RRAM等非易失存储器件的发展和应用侧日益提升的高效访存需求,存算一体技术自ISCA'16的PRIME与ISAAC开始迎来了复兴。今天的典型存算一体技术包括面向矩阵向量乘的模拟域存内计算、面向逻辑计算的数字域存内计算以及在存储阵列外放置计算单元的近存储计算。
在ISCA 2025,存算一体的相关文章呈现出近存储计算成为主流、由「架构设计」到「软件栈-架构协同优化」的发展趋势,表明体系结构领域愈加关注存算一体的生态建设,在追求高性能、高能效之余还要做到硬件可用、好用。
韩国首尔国立大学Hyojin Sung教授团队的ATiM和苏黎世联邦理工学院Lana Josipović教授团队与加州大学圣地亚哥分校的Tajana Rosing教授团队联合提出的OptiPIM是两篇典型的存算一体编译优化工作,两者均面向DRAM存算一体架构,基于架构特性分析,将算子映射问题形式化为可自动求解的优化任务,从而自动生成可执行代码及优化的数据布局。
值得一提的是,这两项工作均已开源,并获得了Artifact Available, Artifact Evaluated以及Results Reproduced三个Badge。ATiM面向商用存算一体产品UPMEM设计了基于搜索的优化张量编译器,通过复用并扩展TVM的调度原语,进行主机侧与存算一体单元的联合编译寻优与代码生成,自动搜寻最优的tiling、并行与缓存策略。
基于TVM,ATiM提升了UPMEM架构的软件可编程性,用户无需手写UPMEM的低级代码即可获得高达8.21×的性能加速。OptiPIM更注重面向广义DRAM存算一体架构(包括近存计算与存内计算),解决数据布局与循环的优化问题。无独有偶,笔者发表在HPCA'25的UniNDP同样对该问题进行优化。
不同于UniNDP关注在细粒度性能建模与基于启发式的映射策略搜索,OptiPIM对性能与约束条件进行粗粒度系统性建模,将算子映射问题描述成整数线性规划(Integer Linear Programming, ILP)问题,4分钟内即可求得算子向DRAM PIM的全局最优映射。OptiPIM同样获得了本次会议的Distinguished Artifact Award奖项。

OptiPIM优化目标
在存内计算架构方面,ISCA 2025收录了三篇文章,数量较之前有所下降,包括一篇RRAM PIM以及两篇SRAM PIM工作。三篇工作均采用系统级的软硬件协同优化方法,形成软件策略和硬件电路的闭环优化,提高计算准确率与能效。
加州大学圣地亚哥分校Mingu Kang 教授团队的HyFlexPIM在RRAM单元上灵活切换single-level cell(SLC)与 multi-level cell(MLC)两种模式,SLC模式存储密度低但可以保证高计算准确率,MLC模式计算存在误差但存储密度较高。HyFlexPIM在算法层利用SVD分解与微调技术,降低重要权重(具有较大梯度、需要高精度计算)的所占比例,从而节省低存储密度SLC的使用,最终兼顾存储密度与计算准确率。
在基于SRAM介质的存内计算方面主要有两篇文章,分别是北京大学孙广宇教授团队联合东南大学司鑫教授团队、后摩智能提出的AIM,以及清华大学李兆麟教授与中山大学王明羽教授团队提出的MagiCache。
AIM关注存内乘法计算中的电路IR-drop问题,在软件层引入汉明率正则项,在电路层支持自适应电压频率动态调整,最终达到了接近70%的IR-drop缓解。
MagiCache针对Cache内计算的技术路径开展系统级优化,硬件层将cache行动态配置为计算行或存储行;软件层设计虚拟计算引擎,基于虚拟寄存器进行缓存空间管理,设计指令链式技术隐藏数据搬运延时,实现40%的缓存利用率提升。

ISCA 2025中出现的存内计算实现方式

在ISCA 2025的纯存储系统优化专题中,研究者们既关注存储访问效率的极限提升,也聚焦于新型攻击对数据安全性的挑战。回顾存储安全领域的奠基工作,Onur Mutlu教授团队在2014年首次揭示了DRAM row hammer现象,开启了对DRAM「读扰动」安全威胁的系统性研究。
时隔十余年,随着DDR5、PUF、存内计算等新技术的出现,row hammer的问题影响变得更加广泛,安全防护与性能开销之间的矛盾愈加突出。
除了安全性之外,大规模数据分析与大模型等AI计算对存储子系统的访问效率提出了更高要求。
针对上述背景,ISCA 2025收录了多篇row hammer与存储系统优化工作,呈现出存储系统向「高效、安全、智能」多维度演进的趋势。
在row hammer防护方面,四篇工作的侧重点各有不同,分别从防护开销、防护方法以及新场景下的安全性问题等方面开展研究。
佐治亚理工大学Moinuddin Qureshi教授团队提出的MoPAC关注在降低row hammer防护带来的性能损失,通过概率行激活计数的方法,在保证同等安全性的前提下降低更新计数器造成的时序开销。
该团队的另一项工作DREAM在存储控制器侧,分析JEDEC DDR5引入的Directed Refresh Management(DRFM)特性对row hammer的影响并进行优化。
在挖掘新的安全性问题方面,英属哥伦比亚大学Prashant Jayaprakash Nair教授团队在「When Mitigations Backfire」一文探讨了DDR5行激活计数(Per Row Activation Counting, PRAC)中存在的timing channel漏洞问题,提出了对应的侧信道攻击方法与防御策略。
Onur Mutlu教授团队的PuDHammer针对DRAM存内计算的多行激活特性,首次在商用DDR芯片上开展了系统性的读扰动影响评估。
在存储系统性能优化方面,阿联酋人工智能大学Chun Jason Xue教授团队提出的ArtMem与AMD提出的Folded Banks两篇文章分别从系统层和架构层开展了相关研究,通过软件智能算法驱动或硬件微架构创新实现对存储访问模式的动态适配,以达到带宽与延时的协同优化。
ArtMem针对数据在多层级异构存储系统(DRAM内存+持久性内存及CXL扩展存储)中的迁移调度进行优化,利用强化学习方法学习数据的访问行为,动态地将数据页(page)放置在合适的存储层级,提高数据访问发生在DRAM中的相对比例,减少不必要的跨存储层级数据迁移开销。
Folded Banks一文将视角聚焦在HBM上,着重解决HBM在随机访问场景下的有效带宽低的问题,创新性地在架构电路层提出将二维存储Bank「折叠」到三维堆栈中,实现短距离垂直互连,降低数据搬运开销,提高行激活的并行度。

Folded Banks存储架构


 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





