


中科院提出GTinker | 会反思的多模态推理大模型,优于最新的 O4-mini
- 2025-07-31 08:00:00
作者 | AICV与前沿
原文链接:https://mp.weixin.qq.com/s/vumjYW0c_-_kRjYieYW9jg
点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型没那么大Tech技术交流群
本文只做学术分享,如有侵权,联系删文,自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
项目地址:https://github.com/jefferyZhan/GThinker
文章地址:https://arxiv.org/abs/2506.0107
动机
目前的多模态大模型推理主要依赖于逻辑和知识为基础的“慢思考”策略——这些虽然在数学和科学等领域有效,但在推理过程中却无法有效地整合视觉信息。因此,这些模型往往无法充分利用视觉信息进行推理,导致在需要多种合理视觉解释和推断的任务中表现不佳。
解决
GThinker引入了“线索反思” 推理模式,它将推断依据视觉线索,并反复重新解释这些线索用于解决不一致之处。在此模式基础上,作者团队提出了一个两阶段的训练流程,包括模式引导的冷启动和DAPO强化学习,旨在实现跨领域的多模态推理能力。
数据方面,作者团队构建了 GThinker-11K,其中包括 7000 条高质量、迭代标注的推理路径和 4000 个精心挑选的强化学习样本。
大量实验表明,GThinker 在具有挑战性的综合多模态推理基准 M3CoT 上达到了 81.5%,超过了最新的 O4-mini 模型,它在通用场景多模态推理基准上平均提高了 2.1%,

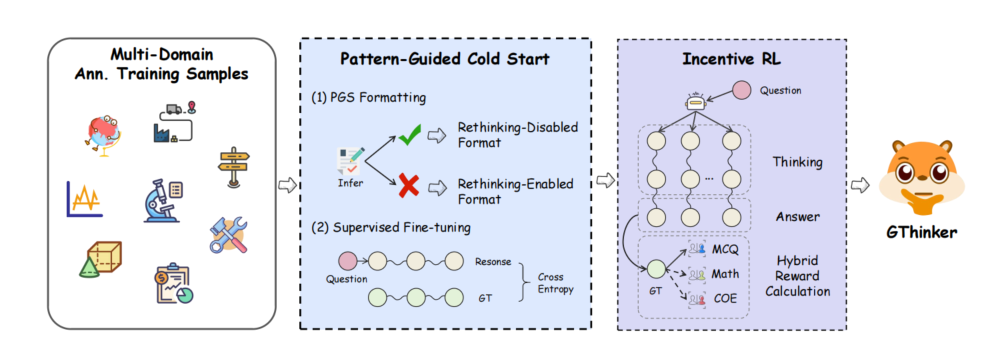
GThinker 的总体训练流程
数据收集

模式引导冷启动
基于上面构造的数据,模型通过有监督的微调训练来采用提示-反思的范式。并引入了模式引导的选择性格式化,根据问题类型定制训练数据。具体来说,首先让基础模型处理训练问题,并将其推理路径与标注进行比较。选择具有错误视觉线索的样本来形成完整的提示再思考序列,涵盖所有三个阶段。剩余的示例则被格式化为自由形式的推理路径。然后,使用这种模式编译的数据对模型进行微调,使它能够根据问题的要求适应性地进行推理或再思考。
结果奖励强化学习
多场景数据构建
广泛收集开源推理数据,并通过 embedding 聚类的方式进行均衡和多样性采样,从中精选包含约 4K 条多场景、多任务的强化学习训练数据集,为泛化能力的提升提供数据保障。
DAPO 训练
相较于 GRPO,DAPO 采用动态采样的方式,保证 batch 样本的有效性,并应用无 KL 和 clip higher 等策略,更适用于长链思考和探索,使模型学会在不同场景下选择最优推理方式。
混合奖励计算
针对选择题、数学题等常见任务类型,分别采用精确匹配、Math-Verify 工具校验的方式计算奖励,对于通用场景下常见的开放式简答题,通过加入格式化响应让模型回答归纳到短语或单词的形式,以应用精确匹配的计算方式,从而确保了奖励信号的准确性和进一步拓展支持任务的多样性


大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!

 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





