


不靠海量数据,如何精准喂养大模型?上交Data Whisperer:免训练数据选择法,10%数据逼近全量效果
- 2025-07-29 14:38:07

本文第一作者王少博为上海交通大学博士生,现于阿里 Qwen 团队实习,此前有 CVPR 满分一作论文。通讯作者为其导师、上海交大助理教授张林峰。本文其他作者来自上交 EPIC Lab、NTU、NUS、微软、上海 AI Lab、港科大(广州)等。
从未微调目标数据集,一个预训练模型竟能自己筛选出「黄金训练样本」?
上海交通大学等团队提出 Data Whisperer —— 首个免训练的注意力驱动数据选择框架。它直接利用预训练模型的上下文学习(ICL)能力,无需额外微调打分模型,仅用 10% 数据就能让微调效果逼近全量数据!
就像一位精通教学的导师,看一眼题库就知道该让学生重点练什么题。

论文标题:Data Whisperer: Efficient Data Selection for Task-Specific LLM Fine-Tuning via Few-Shot In-Context Learning
论文链接:arxiv.org/pdf/2505.12212
GitHub 地址:gszfwsb/Data-Whisperer
关键词:数据选择、上下文学习、小样本泛化、结构对齐
精调大模型,数据挑对才关键
模型说:「别给我扔几百万条数据了,你先告诉我哪些题值得看!」
传统的数据选择方法:
要先训练个打分模型;
要调一堆启发式参数;
要花一堆时间还不一定好用;
而 Data Whisperer 就像摸鱼同学中的学霸 —— 不看全书也能稳拿高分。
方法机制:只靠模型自身,打分挑数据
Data Whisperer 是一种以大模型自身为评估器、完全免训练的数据子集选择方法。
1. ICL 少样本构建
随机采样若干「示范样本」和「查询样本」,构建 ICL 提示;
让待精调的大模型尝试回答这些查询任务;
根据回答质量,给每个「示范样本」打一个分。
2. 引入注意力感知权重
为了让「题目权重」更加合理,Data Whisperer 不只看输出结果;
它利用 Transformer 的注意力权重,度量每个示例对模型推理的「影响力」;
最终打分由模型输出与注意力贡献共同决定,更稳定、更合理。
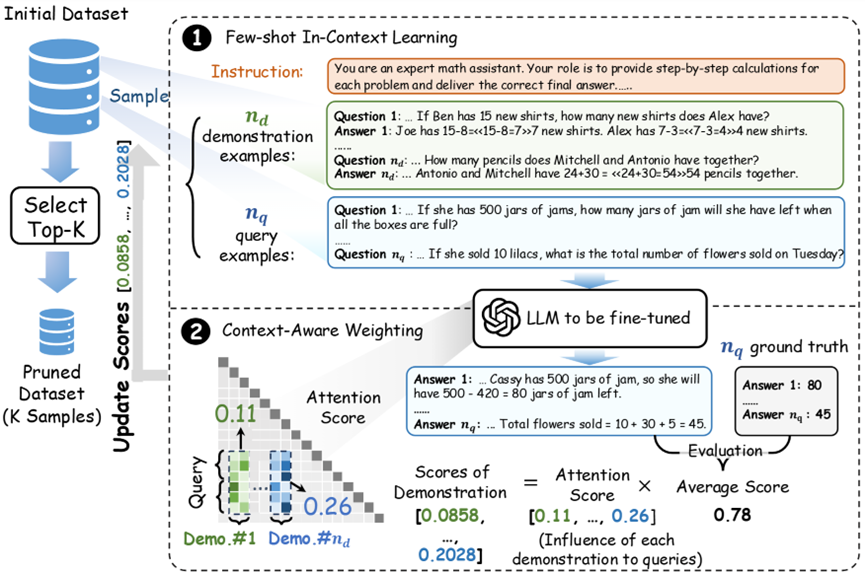
这种打分机制是完全无需训练、无需人工标注的!
Data Whisperer 不是「拍脑袋选题」,理论也站得住脚!
在传统精调中,模型通过梯度下降显式更新参数,比如注意力权重的关键值(Key)矩阵 W_K 和数值(Value)矩阵 W_V:
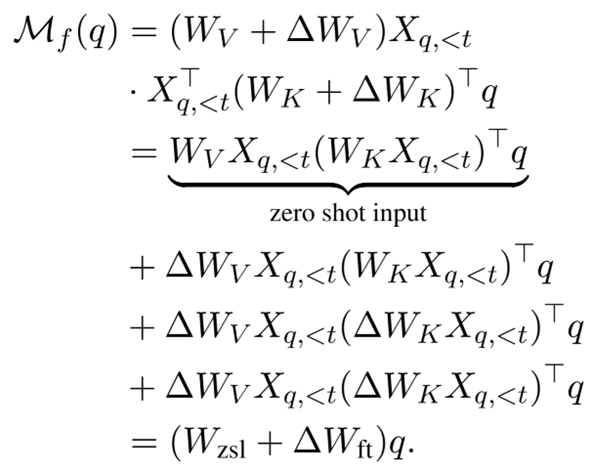
其中 是通过反向传播学到的参数更新。
是通过反向传播学到的参数更新。
而在 ICL 过程中,虽然模型参数固定不变,但通过上下文中的示例(demonstration tokens)对注意力进行加权,使得模型在预测时行为发生了「类精调」式的变化:

这里的  并非真实权重更新,而是通过注意力机制 「模拟出的权重调整」。这正是 Data Whisperer 利用的核心。
并非真实权重更新,而是通过注意力机制 「模拟出的权重调整」。这正是 Data Whisperer 利用的核心。
也就是说,ICL 就像是在不动参数的前提下,用「语言上下文」在行为上更新了模型。
精调谁还全训?我 10% 数据照样打赢!
让我们看看 Data Whisperer 的「压轴战绩」:
GSM8K 数学题:10% 数据打出 72.46%,还比全量数据(71.39%)更高;
DialogSum 总结任务:用 Qwen 模型达到 43%,比最强 SOTA 方法高出 2.5 个点;
BioInstruct 任务也同样提升显著。

别人还在选题,我已经开始精调了
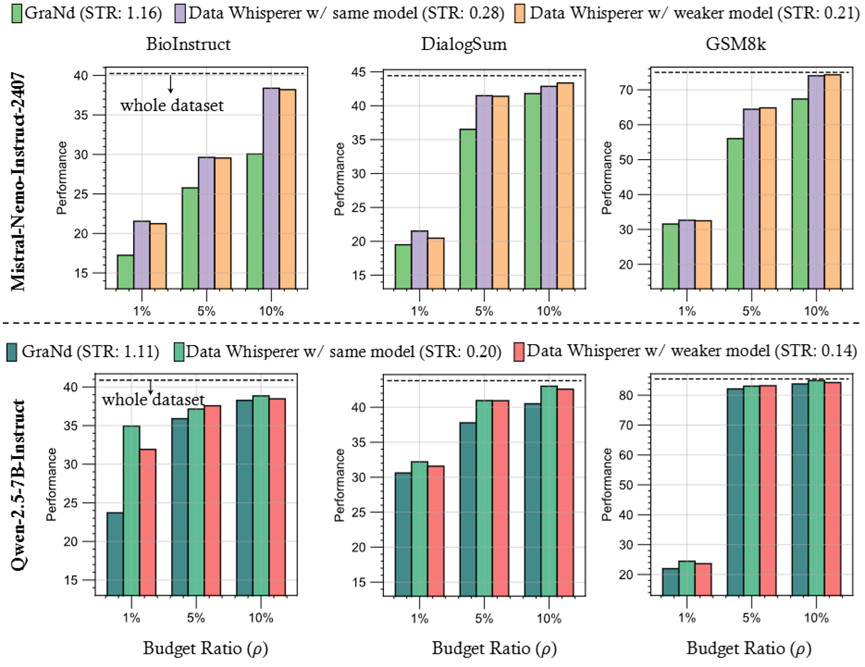
Data Whisperer 引入了一个新的效率指标:Selection-to-Tuning Ratio(STR),即选择过程耗时与全量精调耗时之比。
在该指标下,Data Whisperer 以 STR ≈ 0.03~0.2 的水平,大幅领先现有所有方法。相比之下,许多传统方法(如 Nuggets)STR > 1,意味着「选题还不如直接精调快」。
Data Whisperer 用极低成本完成了模型适配所需的「预判题型」工作。

小模型选题,大模型精调,谁用谁知道!
Data Whisperer 支持弱模型作为「选题器」,强模型作为「学习者」的弱选强训(weak-to-strong)机制。
例如,使用 Qwen-2.5-3B-Instruct 选题、再用 Qwen-2.5-7B-Instruct 精调,最终性能几乎不降,却带来更低计算负担。
Data Whisperer 成功实现了从小模型到大模型间的「知识前置迁移」,适用于资源受限场景下的精调任务。
演示题和查询题怎么配?精细搭配才能挑好!
Data Whisperer 进一步分析了 ICL 中示例(n_d)与查询(n_q)数量对选择效果的影响。
结果显示,n_d=10、n_q=5 是稳定优选配置。在此之后增加样本数量,效果提升趋于饱和。
这表明 Data Whisperer 对输入规模具有良好的鲁棒性,不是靠堆样本,而是真挑核心。

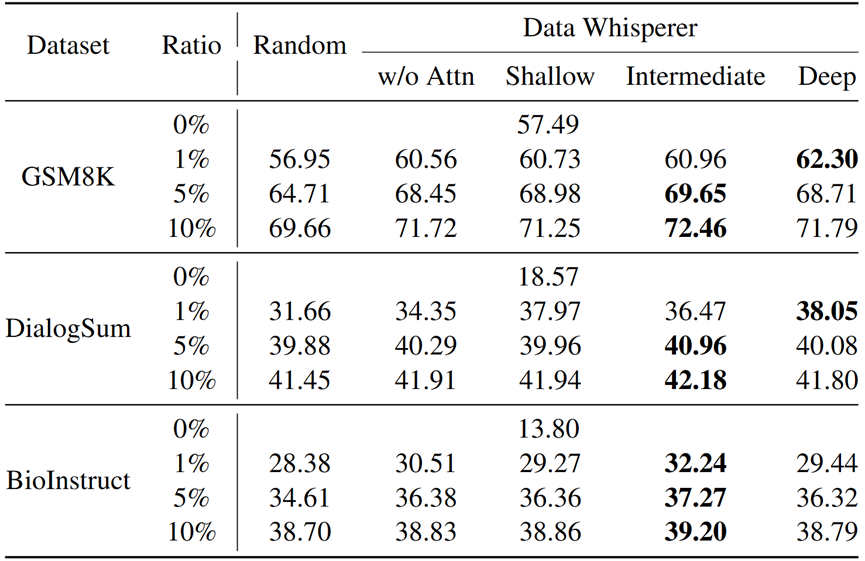
哪层注意力最好用?
Data Whisperer 的注意力打分依赖于 Transformer 的层级结构。作者分别测试了浅层、中层、深层注意力用于打分的效果。
结果发现,中间层(如 Layer13)提供的语义信息更稳定,选题效果更佳,符合语言模型内部语义聚合的层次分布规律。
Data Whisperer 巧妙借力模型结构,使「注意力」真正发挥了「注意」的功能。
模型偏好什么题?简单好懂才是王道
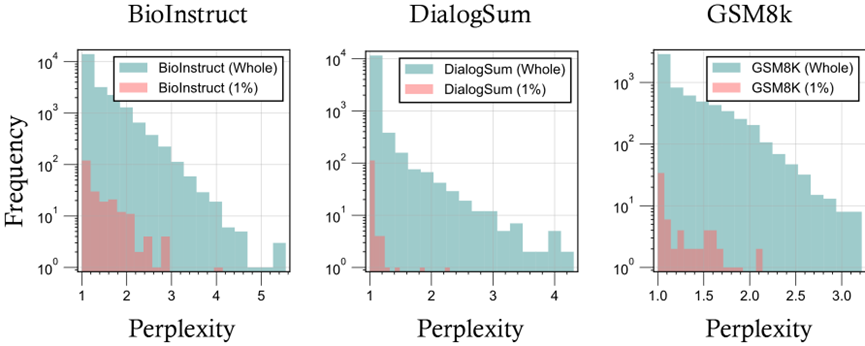
进一步的分析中,作者使用 GPT-4o-mini 对被选中样本的困惑度(perplexity)进行了评估。
发现 Data Whisperer 倾向选择困惑度较低的样本,说明模型更喜欢「简单题」,也符合 Sorscher 等人在小样本学习中的「易例优先」理论。
对比分析:到底比哪些方法强?
Data Whisperer 在所有主流数据选择方法对比中均展现出领先效果:
GraNd:基于梯度;
EL2N:基于预测误差;
CCS:注重多样性;
Nuggets:需要额外精调打分器;
STAFF:组合打分策略。
Data Whisperer 在准确率、效率、稳定性三个维度全面领先,尤其在低预算(1%、5%、10%)场景中优势明显。
Data Whisperer 的秘诀:ICL 就是精调的「影子」
Data Whisperer 并非经验规则,而是基于理论支撑。
论文从注意力机制视角出发,分析了 ICL 过程中上下文样本对模型输出的影响,实质上等价于一种隐式的参数更新。
ICL 调整注意力权重 ≈ Fine-Tuning 调整参数矩阵
两者都是为了「让模型在未来输入中表现更好」。
这一结构上的对应性解释了 Data Whisperer 能有效选出训练子集:它无需调模型参数,就能「预训」出训练效益。
启示与未来方向
Data Whisperer 所倡导的是一种新范式:结构感知、推理驱动的数据选择方法,为 LLM 训练过程引入「自解释、自判断」的机制。
值得注意的是,字节 Seed 最新的工作 (https://arxiv.org/abs/2505.07293),也用了类似 few-shot 和 attention 结合的方法。
接下来值得探索的方向包括:
1. 将方法迁移至法律、医疗、工程等复杂结构任务;
2. 引入人类反馈或语言理解偏好,进一步增强「任务对齐」能力;
3. 结合 prompt 工程,控制示例顺序以提升效果;
4. 与合成数据方法融合,构建任务驱动的多源样本库。
总之,Data Whisperer 并不是简单优化效率的技巧,而是揭示了一个事实:
任务对齐不必依赖人类标签、不必堆数据量。
结构化的推理机制与任务映射,本身就可以引导模型学习方向。
未来的大模型训练也许不再是「知道做什么」,而是「知道问什么」。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com
 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





