


让SDXL实现50倍加速!中山&字节最新对抗训练+双空间判别,单步生成新标杆!性能狂飙
- 2025-07-27 22:09:53
如您有工作需要分享,欢迎联系:aigc_to_future
作者:Yanzuo Lu等
解读:AI生成未来

文章地址:https://arxiv.org/pdf/2507.18569
亮点直击
对抗分布匹配(ADM):提出一种新的对抗学习框架,利用扩散判别器在隐空间对齐真实和伪造分数估计器的预测,替代传统显式散度度量(如KL散度),避免模式崩溃,提升生成多样性。 混合判别器对抗蒸馏:在一步蒸馏任务中,结合隐空间+像素空间的混合判别器,优化预训练生成器,通过ODE轨迹分布损失提供更好的初始化,提升训练稳定性。 DMDX统一流程(预训练+微调):将对抗蒸馏预训练与ADM微调结合,SDXL上实现50倍加速(一步生成),同时保持高保真度,在SD3、CogVideoX等模型上刷新图像/视频生成效率的SOTA。 三次方时间步调度:使生成器更关注高噪声区域,增强样本多样性,改善模式覆盖能力。

总结速览
解决的问题
模式崩溃(Mode Collapse):Distribution Matching Distillation (DMD) 依赖反向KL散度最小化,可能导致模式崩溃(mode-seeking),即学生模型仅学习教师模型的部分模式,忽略多样性。 分布匹配的局限性:现有方法(如DMD、DMD2、MMD、SiD等)依赖于预定义的显式散度度量(如Fisher散度),难以灵活匹配复杂的高维多模态分布。 一步蒸馏的挑战:在极少数步骤(如一步)蒸馏时,学生模型与教师模型的支持集重叠区域不足,容易导致梯度爆炸或消失,初始化质量对性能影响显著。
提出的方案
对抗分布匹配(ADM): 通过扩散判别器(diffusion-based discriminators)以对抗方式对齐真实与伪造分数估计器的潜在预测,替代传统的显式散度度量。 直接在分数蒸馏中引入对抗训练,动态学习数据驱动的分布差异度量。 混合判别器的对抗蒸馏: 在一步蒸馏中,结合隐空间和像素空间的混合判别器(hybrid discriminators),提升预训练生成器的质量。 使用教师模型生成的ODE对(ODE pairs)分布损失替代DMD2中的均方误差(MSE),提供更好的初始化。 统一流程DMDX: 将对抗蒸馏预训练与ADM微调结合,形成端到端流程,显著提升一步蒸馏性能。
应用的技术
对抗训练:利用扩散判别器在隐空间进行对抗学习,动态优化分布匹配。 混合判别器:联合隐空间和像素空间的判别器,增强生成器的多样性。 ODE分布损失:从教师模型中收集ODE轨迹对,通过分布损失优化初始化。 分数蒸馏框架:基于DMD的分数蒸馏理论,结合对抗训练改进模式覆盖能力。
达到的效果
性能提升: 在SDXL上的一步蒸馏性能超越DMD2,且GPU耗时更低。 在SD3-Medium、SD3.5-Large和CogVideoX的多步蒸馏中,为高效图像/视频合成设立新基准。 多样性改善:通过对抗学习避免模式崩溃,生成样本覆盖更广的教师模型分布。 训练稳定性:ODE分布损失和混合判别器提升了初始化和梯度稳定性,减少一步蒸馏的失败风险。
方法
对抗分布匹配
本文不使用预定义的伪造分布与真实分布之间的散度,而是通过对抗判别器采用一种隐式的、数据驱动的差异度量。具体来说,我们的判别器由一个与教师模型相同初始化的冻结潜在扩散模型和多个添加在不同UNet[57]或DiT[49]块上的可训练头部组成。给定从少步生成器输出扩散得到的噪声样本,分数估计器不再像公式(5)中那样求解关于终点和的PF-ODE。
本文设置一个固定的时间步间隔(默认为)并求解关于的PF-ODE,从而可以得到伪造样本和真实样本作为分数预测输入判别器。判别器从冻结骨干层分层聚合特征,并通过多个可学习头部动态加权,建立了一种利用扩散先验和数据驱动可训练动态的自适应差异度量。使用Hinge损失交替训练生成器和判别器。这使得伪造分数预测更接近真实分数预测:


与DMD和DMD2的关系
为了缓解DMD损失中的模式崩溃问题,DMD和DMD2分别额外使用了基于ODE的正则器和基于GAN的正则器进行蒸馏。然而,这两种正则器并未从根本上解决反向KL散度引入的模式寻求行为(如下图4(a)所示),而是通过损失之间的权衡来抵消其影响。在ADM中,对抗损失实际上扮演了DMD损失的角色,通过隐式的、数据驱动的差异度量而非预定义的散度来实现分数蒸馏。因此,在ADM中使用GAN训练的动机与DMD2不同,且不需要额外的正则器。

直观上,可学习的判别器可以近似任何非线性函数来隐式测量分布差异,这可能天然包含了DMD损失中的反向KL散度。如下图3所示,在CogVideoX的多步ADM蒸馏过程中可视化了公式(6)中DMD损失的变化。尽管未直接优化公式(6),结果显示出非常稳定的下降趋势,支持了我们的假设。

对抗蒸馏预训练
为了稳定极具挑战性的一步蒸馏,我们选择通过对合成数据进行对抗蒸馏预训练,为ADM微调提供更好的初始化。我们的预训练配置参考了Rectified Flow的多个方面:1)以离线方式从教师模型收集ODE对;2)通过在ODE对的纯噪声和干净数据样本之间线性插值构建噪声样本;3)将生成器的预测目标改为ODE对的速度。
对于对抗训练,本文分别构建了一个从教师模型初始化的隐空间判别器和一个从SAM模型的视觉编码器初始化的像素空间判别器,如下图2所示。还在骨干网络上添加了多个可训练头部,类似于ADM中的做法。所有这些都有助于提高判别能力,促进学生模型发现教师模型分布中更多的潜在模式。具体来说,设表示生成器预测的PF-ODE终点,其中表示在ODE对之间随机时间步插值的噪声样本。对于隐空间判别器,用另一个随机噪声和时间步对生成器输出进行扩散,得到作为其输入。对于像素空间判别器,生成器输出将首先通过VAE解码器解码,然后输入视觉编码器。基于Hinge损失的训练目标鼓励生成器输出更接近合成数据样本。


通过实验发现,设置平衡系数,可以产生视觉上连贯的结果。
三次方生成器时间步调度
直观上,更高的噪声水平通过减弱潜在表征中的限制性信息来鼓励探索新模式。因此,我们提出对生成器采用三次方时间步调度。该调度通过将均匀的样本进行非线性映射,使值集中在接近的高噪声区域,类似于LADD。
均匀判别器时间步调度
与ADM中判别器首次用于分数蒸馏不同,隐空间判别器在对抗蒸馏工作中较为常见。受SDXL-Lightning启发(他们发现扩散编码器在低时间步关注高频细节,在高时间步关注低频结构),我们为判别器时间步设置均匀的区间,以在预训练中同时捕获这两方面优势。
与LADD的关系
对合成数据进行对抗蒸馏的动机受LADD启发,但存在多处不同:1)通过Rectified Flow风格的ODE对而非随机噪声构建噪声样本;2)开发了促进确定性欧拉采样的三次方生成器时间步调度;3)引入额外的像素空间编码器以增强判别器能力并发现更多模式。
讨论
ADM与ADP的区别
一个关键问题是:这两种带有隐空间判别器的对抗方法有何区别?分数蒸馏的有效性与分数函数在不同噪声水平下的定义相关。而对抗蒸馏仅在时对齐干净数据样本的分布。预训练中的隐空间判别器通过随机扩散生成器输出来捕获不同尺度的信息,而ADM的核心在于同时求解两个分数估计器的PF-ODE。换言之,ADM通过在各分布不同噪声水平的高密度噪声样本额外监督整个去噪过程。
当两个分布的支持集初始重叠较少时,ADM中噪声样本会停留在彼此不熟悉的区域,导致判别器极易区分它们并产生极端梯度信号。而由于高斯噪声的各向同性,ADP中人为为随机扩散样本创建了重叠区域,使判别更困难从而产生相对平滑的梯度。因此,ADM仍属于分数蒸馏(它促使整个概率流更接近),而预训练属于对抗蒸馏(仅关注的干净数据分布)。
预训练的重要性
我们尚未讨论的问题是:为何一步分数蒸馏需要预训练?以DMD损失使用的反向KL散度为例:

当采用一步蒸馏时,生成器输出在视觉保真度和结构完整性上比多步采样更差,导致在某些区域而。此时被积函数趋近于,使得优化过程避开但密度可忽略的区域,这种现象称为"零强迫"。会坍缩到的部分模式子集,如图4(a)所示产生模式寻求行为,训练中表现为梯度消失。反之,扩散模型单步生成的模糊样本也不在教师分布内,导致某些区域而,被积函数发散到,引发数值不稳定和梯度爆炸。
类似地,当学生和教师分布的支持集几乎不重叠时:
前向KL散度在区域趋近 JS散度饱和至常数 Fisher散度可能退化为无定义
因此当该假设不成立时,许多单一散度度量不再适用,如图4(b)所示,具有更多重叠区域的更好初始化变得至关重要。
理论目标
最后一个问题是:为何ADM在理论上优于DMD损失?实际上,采用的Hinge GAN已被证明最小化总变差距离(TVD):
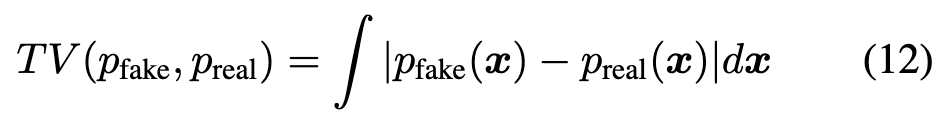
也就是说,当判别器足够丰富且训练良好时,Hinge损失的理论最优解在收敛时会最小化总变差距离(TVD)。当伪造分布与真实分布的支持集重叠极小时,TVD相比反向KL散度具有两个关键优势:1)对称性:TVD无论初始分布如何都产生相同的差异度量,而非对称的反向KL可能出现模式寻求行为并忽略整体分布的其他部分。例如前面图4(c)所示,当而时,TVD保持显著的损失值并提供覆盖该模式的优化方向,而反向KL散度在此情况下会出现梯度消失问题。2)有界性:TVD被限定在区间,因此能减轻训练中异常值的干扰,尤其在我们高维多模态的文本条件图像和视频分布中,避免了反向KL散度因梯度爆炸导致的数值不稳定问题。
实验
模型。对于一步蒸馏,在SDXL-Base上同时采用对抗蒸馏预训练(ADP)和ADM微调,称为DMDX。对于多步蒸馏,我们仅在文生图模型SD3-Medium、SD3.5-Large和文生视频模型CogVideoX-2b、CogVideoX-5b上使用ADM训练。遵循多数同期工作,我们未在文生图模型中使用无分类器引导(CFG),但在文生视频模型尝试了CFG集成实验。
数据集。本文提出的ADP和ADM均不需要视觉数据。对图像生成器,使用JourneyDB中具有高度细节和特异性的文本提示进行训练;对视频生成器,训练提示来自OpenVid-1M、Vript和Open-Sora-Plan-v1.1.0。
评估。图像生成器参照DMD2在COCO 2014的10K提示上进行评估,报告CLIP分数及人类偏好基准PickScore、HPSv2和MPS。但一步定量比较中未包含Hyper-SD,因为一步Hyper-SDXL已通过ReFL直接优化人类反馈,转而比较其在SD3-Medium上提出的TSCD算法(4步Hyper-SD3 LoRA未经ReFL优化)。视频生成器通过包含多维度质量与语义评估的VBench进行评测。
超参数。尽管ADP和ADM需训练多个模型,无需大量调参即可获得满意的视觉保真度与结构完整性。后续实验仅调整生成器学习率,判别器和伪造模型的优化器设置在所有实验中保持一致。除非特别说明延长训练,文生图和文生视频模型分别仅训练8K次(batch size为128和8)。
高效图像合成
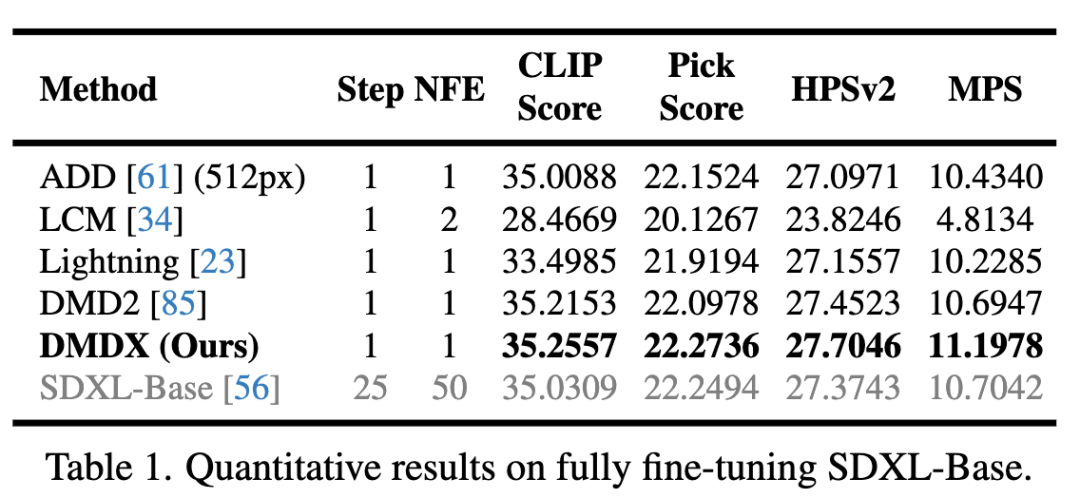
下表1定量比较了嗯问在SDXL-Base上结合ADP与单步ADM蒸馏的两阶段方法与现有一步蒸馏方法。结果显示,本文的方法在图文对齐度和人类偏好上均取得优异表现,这与下图5的定性比较一致(包括更好的人像美学、动物毛发细节、主体-背景分离和物理结构)。

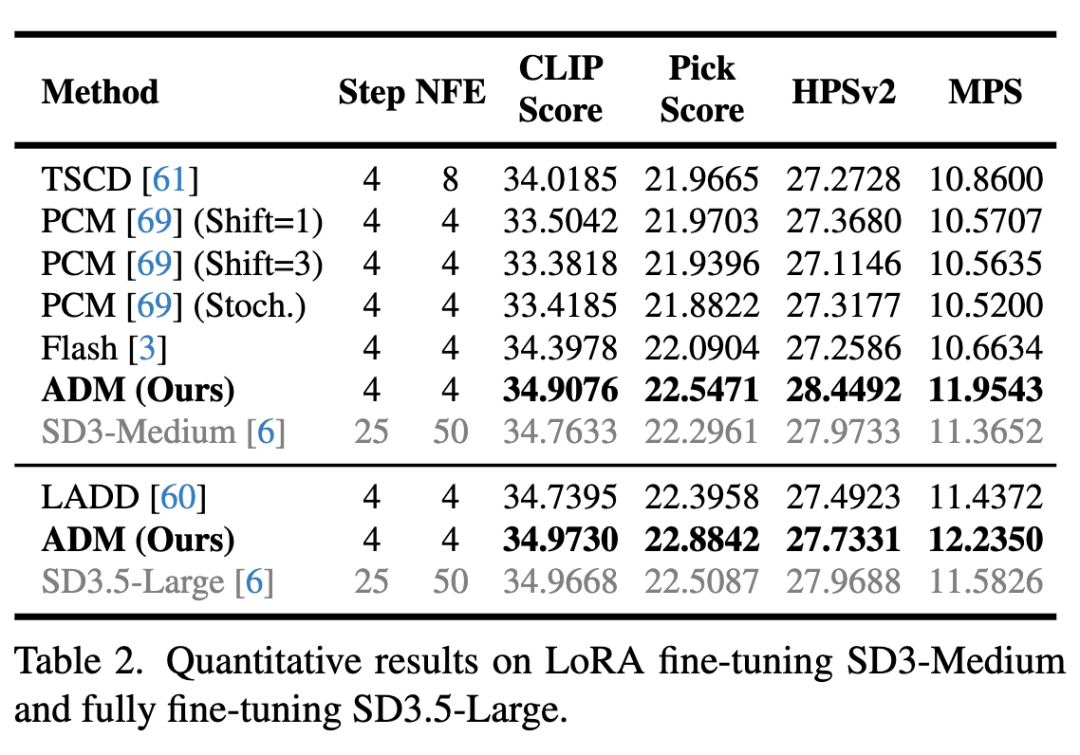
对于多步ADM蒸馏,其可作为独立的分数蒸馏方法。本文尝试了全参数微调和LoRA微调配置,下表2的定量结果证明了本文方法的优越性能。

高效视频合成
如下表3所示,除对CogVideoX两种规模常规进行8步ADM蒸馏外,我们还尝试在文生视频任务中集成无分类器引导(CFG):
真实模型的CFG尺度随机采样于 少步生成器的尺度通过从真实模型值显式减去确定
实验发现该减法偏移量需随目标采样步数减少而逐步增大。伪造模型不使用CFG。VBench结果显示,少步生成器在加速92-96%的同时达到与基础模型相当的性能。

针对2B模型延长训练的额外评估表明(如前面图3所示,DMD损失在8K次迭代时未充分收敛),ADM蒸馏过程中可学习判别器也能近似优化DMD损失。
消融实验
下表4对SDXL-Base全参数微调进行广泛消融研究:

ADP效果:
单次重流过程效果有限(A1),多次有效修正需高昂计算成本 相比广泛采用的DINOv2,SAM因1024px更高分辨率带来更强成像保真度(A2/A5) 像素空间权重需平衡:过大损害结构完整性(A3/A5),过小导致模糊(A4/A5)
ADM效果:
缺少ADP会显著降低性能(B1/B4) 无正则器时,DMD损失性能逊于独立ADM(B1/B2),表明其鲁棒性差 虽然DMD损失优化也受益于ADP(B2/B3),但其分布匹配能力仍弱于ADM(B3/B4)
TTUR的影响。下表5展示了不同TTUR设置对最终性能和训练时长的影响。结果表明,增加TTUR仅带来微弱的性能提升,却使训练时间近乎翻倍,这种权衡显然得不偿失。这凸显了本文提出的ADP在一步蒸馏中的关键作用,同时表明DMD2中的训练不稳定性很可能源于支持集重叠不足。

多样性评估。遵循DMD2的方法,在Partiprompts上为每个提示生成4个不同种子的样本,并在下表6中报告平均成对LPIPS相似度。结果表明,本文的方法在多样性方面显著优于其他方法。


定性比较




局限性
本文意识到一个弱点是教师模型可能需要CFG来产生准确的分数预测。实验表明这是分数蒸馏方法的普遍特性,而非我们方法独有的限制。这限制了该方法在FLUX.1-dev等基于引导蒸馏模型中的应用,这可能是未来研究的一个潜在方向。
参考文献
[1] Adversarial Distribution Matching for Diffusion Distillation Towards Efficient Image and Video Synthesis
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!

 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





