


【源头活水】多模态大模型存在「内心预警」,无需训练,就能识别越狱攻击
- 2025-07-27 18:00:00
“问渠那得清如许,为有源头活水来”,通过前沿领域知识的学习,从其他研究领域得到启发,对研究问题的本质有更清晰的认识和理解,是自我提高的不竭源泉。为此,我们特别精选论文阅读笔记,开辟“源头活水”专栏,帮助你广泛而深入的阅读科研文献,敬请关注!
模型其实 “心里有数”:越狱时隐藏状态在报警
本文核心作者包括姜一雷,谭映水,高欣颜,岳翔宇。
他们的核心发现是:即使 LVLMs 表面上被越狱、生成了不当内容,其隐藏状态中依然保留着拒绝的信号。特别是在模型的中间层,这些信号往往比最终输出更早、更敏感地 “察觉” 到潜在风险。更有趣的是,文字输入和图像输入会激活完全不同的 “安全通路”,也就是说,LVLMs 对不同模态的 “危险感知” 机制是有区分的。
论文已被 ACL2025 main conference 收录。

项目开源 github 链接:https://github.com/leigest519/hiddendetect
arxiv 链接:https://arxiv.org/abs/2502.14744
从 “拒绝语义” 中解码多模态大模型的安全感知

图 1: 基于模型自身激活模式的多模态越狱检测方法。
首先,研究者从模型拒绝回答不安全输入的响应中,统计出一组高频出现的、具有明确拒绝语义的 token(如 “sorry”, “unable”, “unfortunately” 等),并利用 one-hot 编码的方式,在词汇空间中构造出一个 “拒绝语义向量” (RV),作为模型拒绝行为的表示。随后,研究者将模型各层的隐藏状态通过反嵌入层投影回词汇空间,并计算出其与 RV 的余弦相似度,以此衡量当前层所包含的拒绝语义强度。该过程会生成一个长度等于模型层数的向量 F,用于刻画模型在各层对拒绝语义的激活强度。

实验结果显示,F 在安全与不安全输入之间存在显著差异:对于安全样本,F 的整体数值普遍较低;而对于不安全输入,F 通常在中间层逐步升高至峰值,随后在最后几层出现明显回落。此外,无论输入是否安全,F 在最后一层的数值仍普遍高于倒数第二层,表明模型在最终输出前仍保留一定的拒绝倾向。
为进一步分析模型的安全响应机制,研究者构建了三个小样本输入集,分别用于衡量模型在不同类型输入下的拒绝激活表现。其中,安全输入集由无害样本组成,既包含纯文本输入,也包含图文组合输入;另两个不安全输入集则分别对应纯文本攻击样本和图文联合的攻击样本。

如图 2 所示,每组样本都计算出其对应的拒绝强度向量 F,并将不安全输入的 F 与安全输入的 F 相减,得到 “拒绝差异向量” (FDV),用于衡量模型在处理不安全输入时相较于安全输入所产生的激活差异。


图 2: 通过少样本分析方法,识别出模型中对安全最敏感的关键层。
模态不同,响应路径也不同
如图 3 所示,两种模态的 FDV 曲线均表明模型在部分中间层对拒绝信号的响应强度显著高于输出层,说明这些中间层对安全性更加敏感。具体而言,文本输入的拒绝激活差异在较早的层级便迅速增强,而图文输入的响应整体偏后,且强度相对较弱,说明视觉模态的引入在一定程度上削弱了模型拒答机制的早期响应能力。
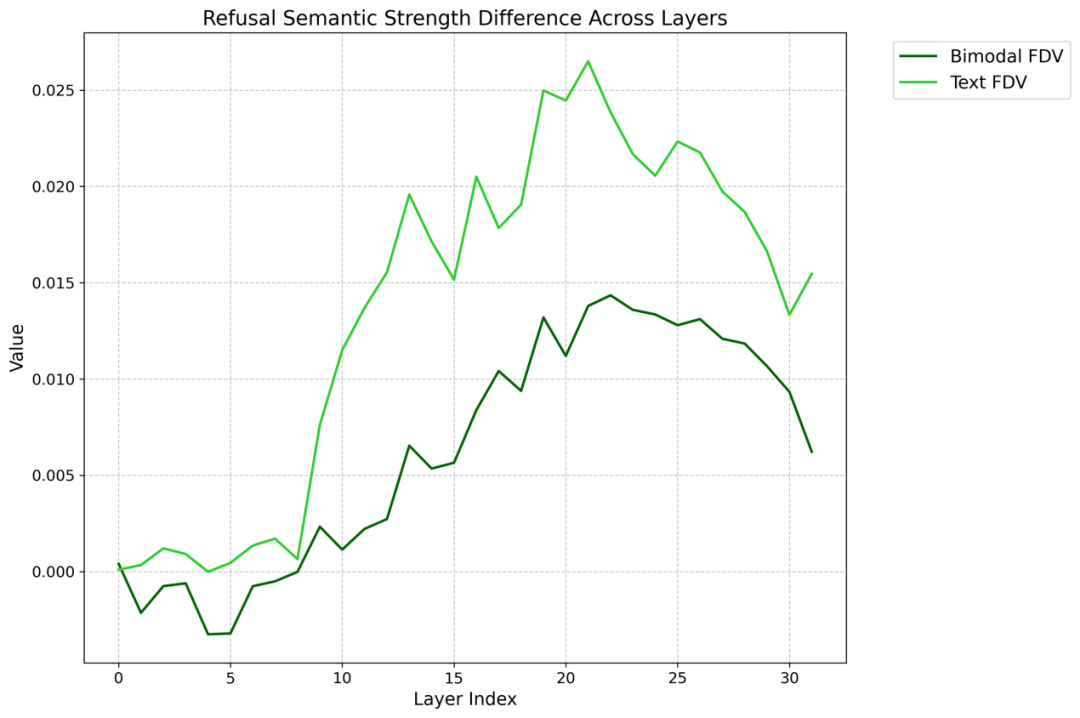
图 3:纯文本样本和跨模态样本的 FDV 曲线。
实验还发现如果模型对拒绝信号的强激活集中在更靠后的层,或者整体激活强度变弱,越狱攻击就更容易成功。有趣的是,研究者发现,仅仅为一条文本攻击提示加上一张图片,就可能让模型的拒绝反应变得延迟,原本中层就能激活的拒绝信号被 “推迟” 到了后层,整体响应强度也降低,从而削弱了模型的安全防护能力。
最终,该小样本分析方法通过 FDV 值成功定位了模型中对不同模态输入安全性最敏感的层。研究者将模型最后一层的差异值作为参考基线,因其对部分不安全输入缺乏足够辨别力;而那些 FDV 显著高于末层的中间层,通常具备更强的安全判别能力。

进一步地,只需累积在这些关键层上的拒绝激活强度,便可有效识别潜在的不安全样本,从而构建出一个高效、无需训练、具备良好泛化能力的越狱检测机制。

实验结果
研究团队在多个主流 LVLM(包括 LLaVA、CogVLM 和 Qwen-VL)上系统评估了所提出的检测方法,涵盖纯文本越狱(如 FigTxt)和跨模态图文攻击(如 FigImg 和 MM-SafetyBench)等多种攻击类型。此外,研究者还在 XSTest 数据集上测试了方法的稳健性。该数据集包含一些安全但易被误判的边界样本,常用于评估检测方法是否过度敏感。实验结果表明,该方法在保持高检测效果的同时,具备良好的鲁棒性和泛化能力。

可视化

图 4:每一层隐藏状态中最后一个 token 的 logits 被投影到由拒绝向量(RV)及其正交方向构成的语义平面。
结论与展望
安全是大模型走向真实世界应用过程中必须优先考虑的问题。HiddenDetect 提出了一种无需训练、基于激活信号的检测方法,为提升多模态模型的安全性提供了新的思路。该方法结构轻量、部署灵活,已在多个模型与攻击类型中展现出良好效果。尽管如此,该方法目前仍主要聚焦于风险提示,尚未对模型行为产生直接调控。未来,研究团队希望进一步拓展方法能力,并深入探索模态信息与模型安全性的内在关联,推动多模态大模型朝着更可靠、更可控的方向发展。
作者团队来自淘天集团算法技术 - 未来实验室团队和香港中文大学 MMLab。未来生活实验室致力于建设面向未来的生活和消费方式,进一步提升用户体验和商家经营效果。实验室聚焦大模型、多模态等 AI 技术方向,致力于打造大模型相关基础算法、模型能力和各类 AINative 应用,引领 AI 在生活消费领域的技术创新。
 本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
收藏,分享、在看,给个三连击呗!

 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





