官方揭秘ChatGPT Agent背后原理!通过强化学习让模型自主探索最佳工具组合
- 2025-07-23 18:36:15
不圆 发自 凹非寺
量子位 | 公众号 QbitAI
ChatGPT Agent的技术内幕,被官方披露了。
就在OpenAI官方推出其最强智能体后,外界褒与贬的热议都没停过……但不论如何,都被视为智能体方向上标志性的一步,是OpenAI一个全新的开端。
关于更进一步的Agent Mode的工作原理,OpenAI开发团队在和投资方红杉资本的圆桌谈话中做了详细解析,还回答了几个值得关注的问题。
这是OpenAI官方首次详细解析ChatGPT Agent功能背后的原理。

ChatGPT Agent由以下四个部分组成:
Deep Research(基于文本的研究智能体) Operator(基于GUI/操作的计算机智能体) 其他新工具(终端、图像生成、API调用等) 通过共享状态进行整合
然而,智能体也不是想要整合就能整合的,在这场谈话中,OpenAI透露了他们的训练方法,以及他们为ChatGPT Agent做出的组织调整。
量子位提取并总结了一些关键信息,让我们一起来看。
歪打正着的起源
在正式走近ChatGPT Agent之前,让我们介绍一下这次谈话的几位主角,他们分别是OpenAI团队核心成员Isa Fulford、Casey Chu和孙之清。
Isa Fulford,斯坦福大学计算机科学硕士(人机交互方向),2022年11月加入OpenAI,现主导ChatGPT Agent的交互范式设计。 Casey Chu,OpenAI资深员工,斯坦福数学硕士,领导GPT-4视觉输入初始原型开发,现为Operator/ChatGPT Agent技术负责人。 孙之清,95后北大校友,DeepResearch负责人,去年6月博士还没毕业就加入了OpenAI,在后训练团队担任研究科学家,已参与OpenAI的诸多核心项目。
在这次的谈话中,他们介绍了ChatGPT Agent的起源:
我们团队分别开发了Operator和Deep Research,在分析用户请求时发现,Deep Research的用户非常希望模型能够访问需要付费订阅的内容或有门槛的资源,而Operator恰好具备这种能力。
通过分析Operator的用户提示发现,很多用户实际上试图用它执行Deep Research类型的任务。
除了整合两个核心工具,我们还添加了终端、图像生成等多项功能。
原本两个功能不同的智能体,就这样在用户的“错用”下合二为一,变成了一个更通用的ChatGPT Agent。
1+1>2,怎么做到的?
简单地说,ChatGPT Agent是Deep Research和Operator合作的成果。
Deep Research擅长文本阅读与综合报告,而Operator擅长视觉交互(如点击、输入、滚动);在此基础上,ChatGPT Agent补足了Deep Research不擅长多轮对话的短板,能持续协作;又能在保持视觉交互的同时,执行研究类任务。
但它们是如何整合到一起的呢?
在这次圆桌谈话中,ChatGPT Agent团队首次披露了他们的训练方法:将所有工具集成至虚拟机,通过强化学习让模型自主探索最佳工具组合。
具体来说,在训练过程中,模型被赋予所有可用的工具,例如文本浏览器、虚拟浏览器、终端工具和图像生成工具,它们都运行在同一个虚拟机(VM)环境中,并且所有工具都共享状态,类似于一台电脑上不同应用程序访问相同文件系统的方式。
这种设计使ChatGPT Agent能高效处理互联网、文件系统和代码等交互任务。研究团队没有预先指定工具使用规则,而是让模型通过强化学习自行发现最佳策略。
研究团队会创建一系列难度较高的任务,而模型需要调用已有的工具来完成任务。通过奖励机制,如果模型能够高效且正确地完成任务,它就会得到奖励,从而学会如何更好地执行任务。
训练后的模型能够通过实验自主学习如何高效、正确地完成任务,并流畅地在各种工具之间切换,而无需被明确告知何时使用何种工具。
例如,如果任务要求研究餐厅并预订,模型可能会先使用文本浏览器进行研究,然后切换到图形用户界面(GUI)浏览器查看食物图片或预订可用性(这通常需要实际的GUI浏览器来处理JavaScript元素)。
ChatGPT Agent团队认为这种训练方法潜力巨大。ChatGPT Agent目前仅为最简可行产品(Minimum Viable Product,MVP),但已经展现出强大的能力。同样的强化学习算法也适用于Deep Research、Operator,研究团队在短时间内就取得了这些成果,未来还有很大提升空间。
在交互性方面,ChatGPT Agent团队主要关注端到端性能,从用户提示到任务完成。
ChatGPT Agent在与用户交互方面表现良好,部分原因是它在训练中纳入了多样化的任务轨迹,用户可随时干预,提供澄清或更正,它也能根据反馈调整行为。
ChatGPT Agent的开发可追溯到2017年的World of Bits项目,最大的变化是训练规模的提升,无论是预训练还是强化学习,计算量可能增加了数十万倍,使ChatGPT Agent的短时间开发得以实现。
小团队能成大事
OpenAI为了打造ChatGPT Agent,对其下的组织架构做出了调整。
比方说参与这次圆桌谈话的Isa Fulford和孙之清,是Deep Research团队的核心成员,而Casey Chu是Operator的技术负责人。
简单地讲,ChatGPT Agent团队由Deep Research和Operator的研究与应用团队合并而成。

这个团队的总人数并不多,Deep Research团队最初只有3-4人,Operator团队约6-8人,合并在一起,加上产品和设计人员,也就20到35人,但他们花几个月就完成了这个项目。
他们在谈话中表示,ChatGPT Agent团队对研究与应用的界限并不严格,应用工程师参与模型训练,研究人员也参与模型部署。
研究与应用团队紧密合作,从定义产品功能到模型训练均以用户场景为导向。
这种跨职能合作使项目充满活力,团队氛围非常好。
虽然ChatGPT Agent尚未完全实现所有目标,但这种组织框架使他们能够快速迭代。
安全机制与未来发展
谈话还提到了ChatGPT Agent遇到的挑战,以及他们对未来的展望。
在训练过程中,ChatGPT Agent遇到的最大的挑战是训练的稳定性问题,ChatGPT Agent需同时处理多种新工具,且都在同一虚拟机环境中运行。这就需要同时运行成千上万的虚拟机访问网络,经常遇到网站宕机、API限制或网络容量不足等问题。
某些网站可能因流量过载而暂时不可用,或者API调用因速率限制而失败,这要求研究团队在训练中加入鲁棒性机制,确保ChatGPT Agent能处理这些异常情况。
另外,由于ChatGPT Agent能够执行具有外部副作用的操作(例如购买物品),研究团队在安全方面投入了大量精力,实施了多层次安全措施,包括以下四个方面:
实时监控系统检测异常行为,若发现可疑操作会立即暂停任务 执行敏感操作前强制用户确认 生物风险专项防护 支持用户随时接管操作
研究团队特别关注了生物风险等严重问题,例如防止ChatGPT Agent被用于创建生物武器。

对于未来的展望,ChatGPT Agent团队在这次谈话中表示,OpenAI倾向于打造一个通用的超级智能体。
虽然单一智能体模型在扩展性和通用性上更具潜力,但研究团队希望通过持续优化,让ChatGPT Agent能够无缝处理从简单查询到复杂工作流的各种任务,减少用户对多个专用模型的依赖。
从市场价值的角度来看,定制化模型可能更优,但从训练角度看,通用智能体能更好地利用技能的可迁移特性。研究团队也在探索如何通过强化学习进一步提高ChatGPT Agent的泛化能力,在遇到全新任务时快速适应,而无需大量额外训练数据。
未来,ChatGPT Agent可能通过学习用户反馈,动态调整其行为模式,进一步提升任务完成的精准度。
总的来说,ChatGPT Agent的未来发展方向如下:
增强多轮对话与个性化记忆 开发主动服务能力 探索更自然的交互范式 提升复杂任务(如数据分析)的完成度
目前ChatGPT Agent已开放使用,Plus用户每月有40次使用额度。
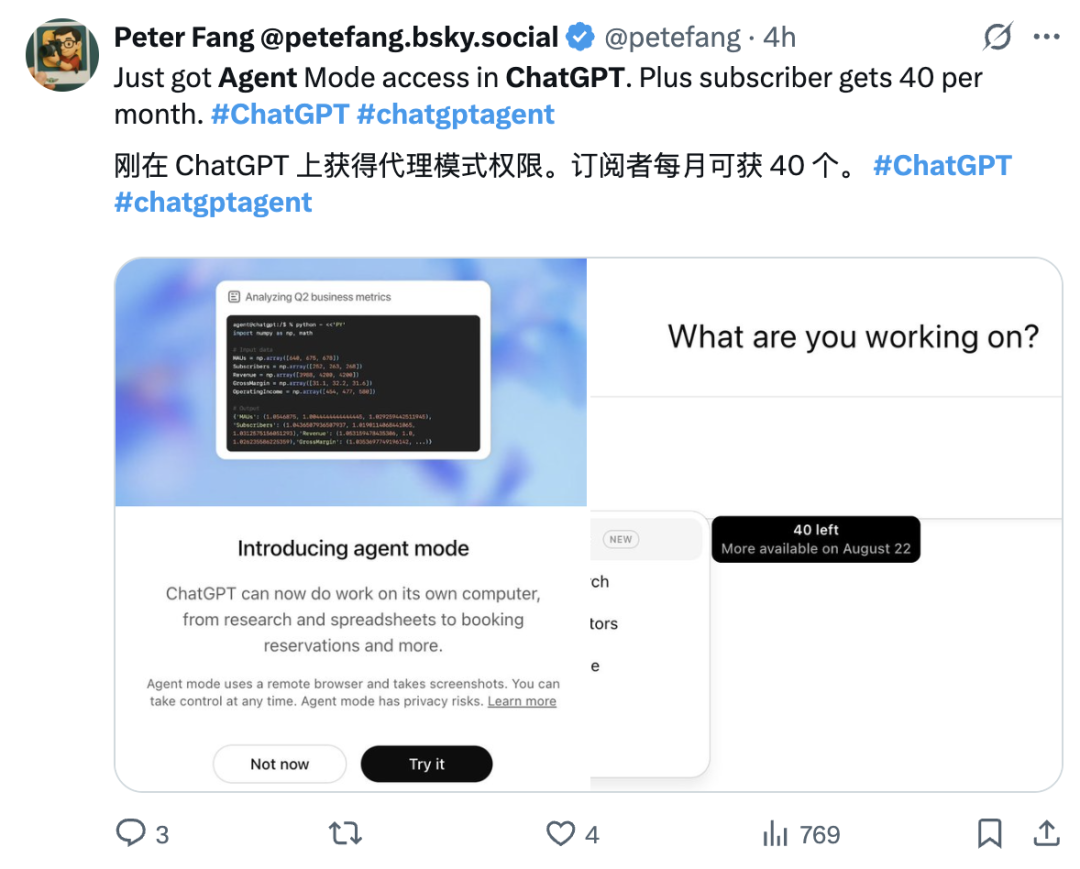
ChatGPT Agent的研究团队在采访中表示,他们有意设计了一个开放式的智能体,鼓励用户探索其潜力。
参考链接:
[1]https://x.com/sonyatweetybird/status/1947718831075693055?s=46
[2]https://www.youtube.com/watch?v=YNWWu0aZ5pY
[3]https://x.com/OpenAI/status/1945904743148323285
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
 扫码添加小助手,发送「姓名+公司+职位」申请入群~
扫码添加小助手,发送「姓名+公司+职位」申请入群~
🌟 点亮星标 🌟
 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊