


没有K2这把刷子,Kimi复仇还真的难说——月之暗面Kimi K2技术报告一览~
- 2025-07-23 09:30:00
点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型没那么大Tech技术交流群
本文只做学术分享,如有侵权,联系删文,自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
写在前面
不久前,月之暗面(Moonshot AI)正式开源Kimi-K2 模型,这款模型具有1万亿总参数,320亿激活参数,专为长上下文、代码、推理和Agentic行为而设计。在众多大模型还在聚焦于回答问题时,月之暗面团队已经把目光转向了如何解决问题。Kimi-K2的诞生,不仅是模型参数和性能的一次突破,更是在实际应用场景中为用户提供了更加智能、高效的解决方案。它能够调用工具、编写代码、分析数据,甚至帮助用户完成跨国旅行预订等复杂任务,真正实现了从“思考”到“行动”的跨越。
在发布之后,Kimi K2 的表现十分亮眼。在 OpenRouter 平台上,其 token 消耗量迅速超越了马斯克的 xAI Grok 4,登顶全球 API 调用榜。同时,在 GitHub 上相关项目激增 200%,Hugging Face 上的下载量也在短时间内突破 10 万次。社区中对它的评价极高,被称为 “唯一在编码和 Agent 任务上超越 Claude 4 的开源模型”“中文创意写作吊打 R1”。
那么,Kimi K2 究竟有何独特之处,能在众多大模型中脱颖而出呢?随着昨天 Kimi K2 技术报告的发布,我们或许能从中找到答案。
技术报告链接:https://github.com/MoonshotAI/Kimi-K2/blob/main/tech_report.pdf
多维度基准测试领先
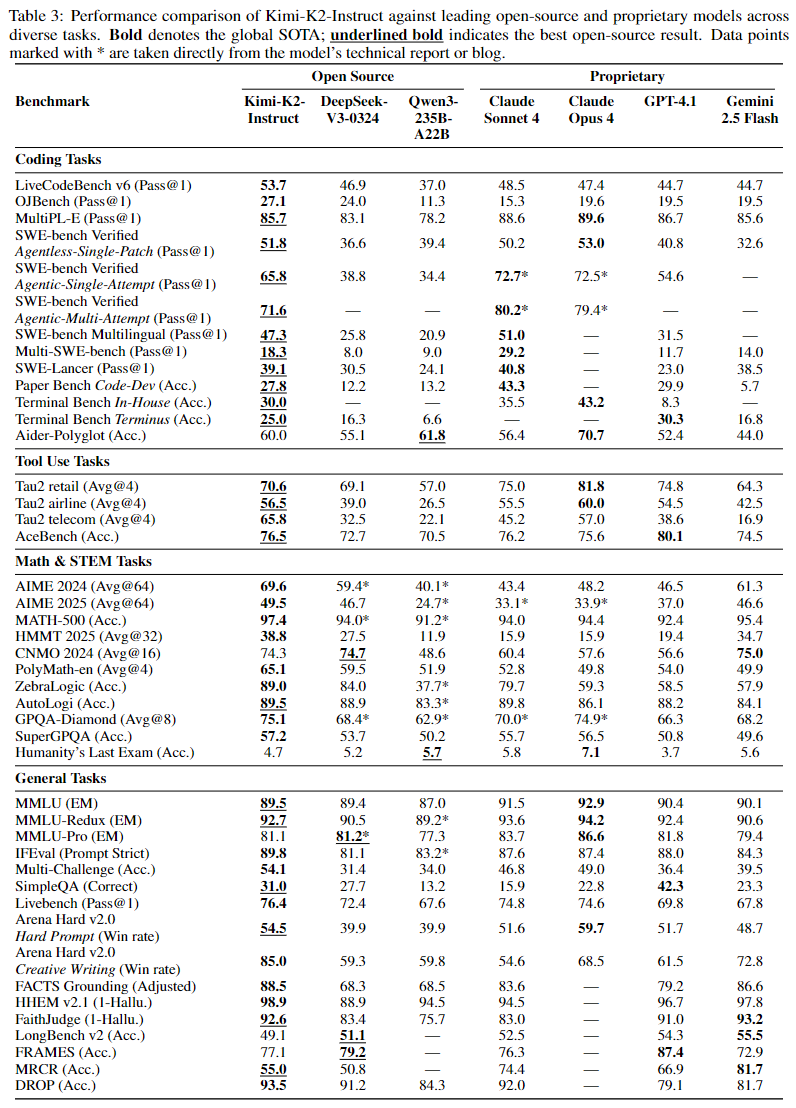
在多项基准测试中,Kimi-K2的表现十分亮眼。在代表工具调用能力的AceBench测试中,Kimi-K2取得了76.5%的成绩;在数学推理能力测试AIME 2024中,得分达到69.6%。
这些成绩不仅超过了许多开源模型,甚至在某些方面超越了部分闭源模型。
在一些特定的代码生成和复杂推理任务中,Kimi-K2展现出了与模型参数规模相匹配的卓越性能,证明了其在实际应用场景中的有效性和可靠性。

模型核心亮点
混合专家架构革新
Kimi-K2采用了混合专家(MoE)架构,这一架构的独特之处在于它拥有384个专家模块,在处理每个token时,仅激活其中8个专家以及1个共享专家用于全局上下文处理。这种设计使得模型在拥有高达1万亿总参数的同时,每次推理的激活参数仅为320亿,实现了“按需计算”,极大地提高了计算效率。与此同时,模型支持128K的上下文窗口,意味着它能够一次性处理大量文本信息,例如可以一次读完一本《三体》并据此撰写书评,这对于需要处理长文档或复杂任务的场景非常有帮助。
为了进一步优化训练过程,月之暗面团队专门为MoE架构设计了MuonClip优化器。在训练过程中,MoE架构由于其特殊的结构容易出现训练不稳定的情况,而MuonClip优化器通过采用QK-clip技术,即对注意力分数进行约束,对Q/K矩阵进行重新缩放,有效地解决了这一问题。在15.5万亿token的训练数据上,Kimi-K2利用MuonClip优化器实现了稳定训练,没有出现一次loss spike,这在超大规模模型训练中是非常难得的成果。
专注Agentic Intelligence
Kimi-K2与传统聊天机器人有着本质区别,它被设计为专注于Agentic Intelligence,即从单纯的语言交互迈向实际行动。例如,在无代码工具调用方面,用户只需简单描述任务,Kimi-K2就能自动选择并组合合适的工具,像搜索、邮件、日历等。这意味着用户无需具备专业的编程知识,就能通过自然语言指令让模型帮助完成一系列复杂任务。
在代码级任务处理上,Kimi-K2展现出了强大的能力。在SWE-bench Verified测试中,其单次尝试准确率达到了65.8%,超过了GPT-4.1的54.6%。不仅如此,Kimi-K2还支持多语言代码编写,从常见的Python到较为复杂的Rust等语言都能轻松应对,甚至能够自动将Flask项目迁移到Rust并成功跑通测试,这对于开发者来说无疑是一个强大的助力工具。

技术报告深度解读
模型架构细节
Kimi K2 采用了典型的稀疏 MoE(Mixture of Experts)架构,总参数规模达 1 万亿,然而其推理时活跃参数仅 320 亿,这一独特设计在保证模型强大表达能力的同时,极大地优化了计算效率。其架构中包含 384 个前馈专家模块(FFN Experts),在每一步推理中,仅激活其中 8 个专家以及 1 个共享 FFN 。与其他模型相比,如 GPT-4(估测激活约 550 亿)或 DeepSeek V3(激活参数 370 亿),Kimi K2 在激活参数的控制上显得更为激进,使得其在推理过程中资源消耗更低,运行更加高效。
在注意力机制方面,K2 使用 MLA(Multi - head Latent Attention)结构替代传统的密集注意力(dense attention)。这一改变意义重大,传统的密集注意力机制在处理大规模数据时计算量巨大,而 MLA 结构有效减少了计算量和带宽压力。同时,K2 将每层的注意力头数量降至 64 个,相比同类模型进一步降低了推理过程中的资源消耗,这使得模型在处理长上下文时具有更好的表现。例如,在处理长篇文档时,能够更准确地捕捉文本中不同部分之间的关联,从而更好地理解文档的整体含义。
此外,Kimi K2 的词表设计也独具匠心,拥有 160K 的词表。这意味着在语言建模任务中,它具有更强的长尾 token 支撑能力,尤其在处理中文、多语种或专业术语任务时更具优势。丰富的词表能够更精准地表达各种复杂的概念和语义,避免因词汇不足而导致的信息丢失或表达不准确。

训练数据与方法
优化器的创新选择
在 Kimi K2 的预训练阶段,训练稳定性至关重要。传统的 Adam 系列优化器在万亿规模训练中容易出现 attention logits 爆炸的问题,进而导致 loss spike,严重影响训练的稳定性和模型性能。K2 团队毅然抛弃了传统的 Adam 优化器,创新性地采用了 MuonClip 优化器。
MuonClip 优化器的核心在于融合了 QK - Clip 机制。该机制会定期检查模型注意力的关键参数 ——query 和 key,如果它们的值过大,就自动进行 “收紧” 操作,从源头上抑制 logits 的增长,防止计算过程出现异常,从而显著提升了训练稳定性。借助 MuonClip 优化器,K2 在 15.5 万亿 token 的预训练过程中成功实现了零损失 spike,确保了大规模训练能够持续、稳定地进行,为模型的高质量训练奠定了坚实基础。

数据处理与利用的革新
在高质量语料稀缺的现实情况下,提升训练数据的效率成为关键。K2 团队致力于通过提升每 token 的有效学习信号(即 token 效用)来增强训练效率,避免因重复训练导致的过拟合问题。
对于知识类文本,团队采用了 “重述法”,即不是让模型简单地重复阅读相同内容,而是换着不同的说法对知识进行再次表述,从而让模型从多个角度理解知识,加深对知识的掌握程度。在处理数学类文本时,将原本枯燥的教材式内容改写成更易理解的 “学习笔记” 风格,这种方式更贴合人类的学习习惯,有助于模型更好地理解数学概念和解题思路。同时,还加入了多语言版本的翻译文本,极大地拓宽了模型的学习视野,使其能够接触到更丰富多样的知识表达方式,增强了模型对不同语言和知识体系的适应能力。
通过这些数据处理与利用的革新策略,K2 的训练数据覆盖了网页、代码、数学、知识四大板块,并且所有数据都经过了严格的质量筛选,确保模型学习到的都是最有价值、最准确的信息。实验结果也证明了这些策略的有效性,用重写 10 次的数据训练 1 轮,其准确率超过了用原始数据训练 10 轮的结果 。


后训练技术提升
在完成预训练后,Kimi-K2进行了一系列后训练操作以提升模型性能。其中包括大规模代理数据合成pipeline,通过构建这一pipeline,能够生成大量多轮工具使用场景的合成数据,覆盖数百领域、数千工具。这些高质量的合成数据经过LLM评估筛选后用于训练,进一步提升了模型在工具使用和复杂任务处理方面的能力。
(一)大规模 Agentic Tool Use 数据合成
为了赋予模型强大的工具使用能力,K2 团队构建了大规模 Agentic Tool Use 数据合成 pipeline。这一过程犹如构建了一个庞大而复杂的 “智能体训练工厂”。
首先,从各种领域中广泛收集工具,这些工具既包括真实的 MCP(模型上下文协议)工具,也涵盖了人工合成的工具,数量多达数千种,覆盖了金融、机器人控制等众多领域。基于这些工具,生成了数百个具有不同工具集的智能体。然后,利用工具模拟器搭建模拟环境,让智能体在其中进行 “实践”,模拟真实用户的交互行为以及工具的执行环境,包括环境状态的更新和可能出现的随机结果,从而生成多轮工具使用轨迹。在这个过程中,还结合了真实执行沙箱(如编码任务),以确保生成的数据真实可靠。
最后,通过 Judge Agent 依据任务 rubrics 对生成的轨迹质量进行严格判断,只保留高质量样本用于训练。这一过程本质上是一种大规模拒绝采样机制,通过大规模的模拟和严格的质量筛选,结合模拟规模与真实反馈,实现了大范围、高保真的训练数据构建,为模型学习复杂的工具使用能力提供了丰富而优质的素材。
(二)通用强化学习框架的构建
在强化学习阶段,K2 构建了通用强化学习框架,成功地将可验证奖励(RLVR)和自我批判评估奖励相结合,实现了从静态对齐到开放域对齐的重大突破。
在数学、编程等可验证任务中,传统的强化学习方法可以根据明确的正确答案、任务完成情况等可验证的奖励信号,对模型的表现进行准确评估,并持续更新和改进对模型能力的评价,从而引导模型不断优化。然而,在生成文本、撰写报告等不可验证任务中,由于缺乏明确、客观的即时奖励信号,传统强化学习方法往往难以发挥作用。
为了解决这一难题,K2 引入了自我批判评估奖励机制,让模型充当自己的 “评判家”。模型会依据一套明确的标准,如语言清晰度、对话连贯性、是否存在啰嗦或拍马屁等情况,对自己的输出结果进行自我评估,并给出相应的奖励分。同时,通过引入一些规则约束,如 “不要无脑称赞用户”,避免模型生成套路化或迎合性的回答。此外,利用可验证任务训练出的 critic 模型,为开放任务提供奖励信号,并通过迭代式的 “生成 → 自评 → 再训练” 过程,持续提升模型在不可验证任务中的泛化性能,形成了一个闭环优化系统。这种创新的强化学习框架使得 K2 能够在各种复杂任务中不断提升自身能力,更好地适应多样化的应用场景。
局限与未来展望
Kimi K2 在内部测试中被发现存在一些局限性,主要包括:
处理高难度推理任务或工具定义不清晰时,模型可能生成过多 tokens,导致输出被截断或工具调用不完整。
若在不必要的场景下启用工具使用功能,部分任务的性能可能下降。
在构建完整软件项目时,单轮提示(one-shot prompting)的成功率不如在代理式编码框架下使用 K2 的效果。
团队表示正致力于解决这些问题,并期待更多用户反馈以进一步优化模型。
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!

 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





