


ACM MM 2025 | EventVAD:7B参数免训练,视频异常检测新SOTA
- 2025-07-20 11:11:28

来自北京大学,清华大学的研究团队联手京东(JD.com)在 ACM MM 2025 发表了一种以事件为中心低成本高效的 Training-Free 视频异常检测框架 EventVAD,论文第一作者邵轶骅目前为北京大学学术访问学生,项目负责人为来自京东(JD.com)的算法研究员马傲,目前代码和数据已全面开源。
现有视频异常检测(Video Anomaly Detection, VAD)方法中,有监督方法依赖大量领域内训练数据,对未见过的异常场景泛化能力薄弱;而无需训练的方法虽借助大语言模型(LLMs)的世界知识实现检测,但存在细粒度视觉时序定位不足、事件理解不连贯、模型参数冗余等问题。
为此,来自北大、清华和京东(JD.com)的研究团队提出了一种全新的视频异常检测框架 ——EventVAD。该框架通过动态图架构与多模态大模型(MLLMs)的时序事件推理结合,在减少模型参数的同时,显著提升了异常检测的精度和效率。实验结果显示,EventVAD 在 UCF-Crime 和 XD-Violence 两大数据集上均超越现有 SOTA 方法,成为无需训练场景下的新标杆。

论文标题:EventVAD: Training-Free Event-Aware Video Anomaly Detection
论文链接:https://arxiv.org/abs/2504.13092
代码开源:https://github.com/YihuaJerry/EventVAD
研究背景和动机
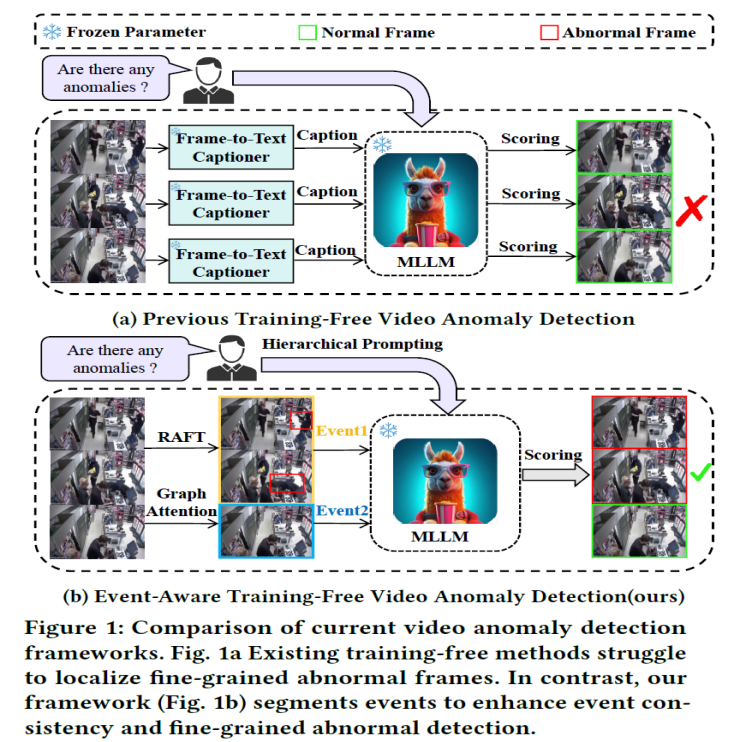
视频异常检测(VAD)的核心目标是精准定位视频中的异常帧,但现有方法存在显著局限:
有监督方法依赖大量标注数据,在新场景中需重新微调,泛化能力差;即使是单类监督或无监督方法,也因缺乏有效标签难以达到理想性能。无需训练方法以 LAVAD 为代表的方法通过视觉问答模型和 LLMs 评分实现异常定位,但存在两大问题:一是依赖至少 130 亿参数的 LLM,导致框架效率低下;二是缺乏对视频的时序理解能力,难以连贯解析长视频,易出现误检和长尾问题。
研究团队发现,无需训练方法的核心瓶颈在于无法对视频中的异常事件进行完整定位,导致后续 LLM 评分存在偏差。受此启发,如上图所示,EventVAD 通过将长视频分割为短事件片段,增强 MLLMs 对视频的时序一致性理解,同时引入动态图模型捕捉帧间关联,最终在减少参数的情况下实现了更高精度的异常检测。
EventVAD 的关键创新

EventVAD 的整体框架包含四个核心模块:事件感知动态图构建、图注意力传播、统计边界检测和事件中心异常评分。通过这一流程,实现了从视频帧特征提取到异常帧精准定位的端到端无需训练检测。
事件感知动态图构建
为捕捉视频的动态时序特征,EventVAD 构建了融合语义与运动信息的动态图模型。结合 CLIP 的语义特征(512 维)和 RAFT 光流的运动特征(128 维),通过融合系数(α=0.75)平衡两种特征,增强事件的时序一致性。通过语义相似度(余弦距离)和运动相似度(指数距离)计算帧间关联,并引入时间衰减因子(γ)抑制长距离帧的冗余关联,突出短时间内的事件连贯性。
图注意力传播
为优化帧级特征并保持时序一致性,EventVAD 设计了基于正交约束的图注意力机制。通过 QR 分解生成正交的查询(Q)、键(K)、值(V)矩阵,避免特征维度坍缩。基于动态图的邻接矩阵计算注意力权重,通过迭代传播更新节点特征,增强事件边界的区分度。

统计边界检测
为精准分割视频中的事件边界,EventVAD 采用了噪声鲁棒的统计方法。复合差异度量中,结合 L2 范数(特征幅度跳变)和余弦距离(方向变化),捕捉事件转换的不连续性。通过 Savitzky-Golay 滤波平滑噪声,计算信号比(局部与全局均值比),并基于中位数绝对偏差(MAD)设置动态阈值,实现无监督的事件边界检测。
事件中心异常评分
为提升 MLLMs 对视频的理解效率,EventVAD 提出分层提示策略。将分割后的事件片段输入 MLLMs,先生成视频内容描述,再基于描述输出异常评分,形成 “自校正” 机制。相比传统帧级分析或全局处理,事件级分析平衡了上下文完整性与特征精细度,减少长视频分析中的误差传播。
实验验证
研究团队在 UCF-Crime 和 XD-Violence 两大基准数据集上对 EventVAD 进行了全面评估,结果显示其性能显著优于现有方法。
UCF-Crime 数据集上的结果
EventVAD 以 70 亿参数实现了 82.03% 的 AUC,超越需 130 亿参数的 LAVAD(提升近 4%),同时优于所有无监督、单类监督方法,甚至超过部分弱监督方法。

XD-Violence 数据集上的结果
使用 XD-Violence 数据集的结果中,在 AP 和 AUC 指标上均比现有无需训练的 SOTA 方法(LAVAD)高出约 5%,验证了其在高分辨率场景下的适应性。

可视化分析
图注意力传播可视化分析如下图,选取 UCF-Crime 数据集中的异常和正常视频样本,对应用图注意力传播前后的帧间关系进行可视化。热力图展示了相应帧区间内帧与帧之间权重关系的变化。

统计边界检测可视化分析如下图,以 UCF-Crime 数据集中的样本为例,对异常视频和正常视频的边界检测过程进行可视化。

消融实验
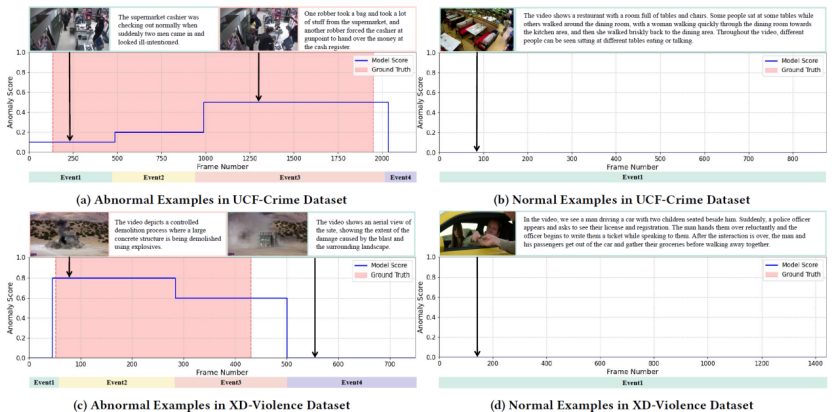
UCF-Crime 和 XD-Violence 数据集中正常样本与异常样本的可视化。对 LAVAD 未能正确检测出异常的样本进行了可视化,下图展示了事件分割结果以及多模态大语言模型(MLLM)的异常帧评分,并与真实标签进行了对比。
总结与展望
EventVAD 作为首个以事件为中心的免训练视频异常检测模型,将推动领域从帧级标注到完整事件级标注的演进。它提供了完整的特征增强,事件划分,异常评分的免真值异常检测基础,极大减少了人工标注的成本和重新训练的开销。未来,随着视频理解模型的星期,EventVAD 这类以事件为中心的视频异常检测范式将为视频细粒度理解提供基础。期待基于 EventVAD 涌现更多创新的算法,加速视频帧级异常检测的发展。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







