


超越O4-mini,多模态大模型终于学会回头「看」:中科院自动化所提出GThinker模型
- 2025-07-19 11:13:37

尽管多模态大模型在数学、科学等结构化任务中取得了长足进步,但在需要灵活解读视觉信息的通用场景下,其性能提升瓶颈依然显著。现有模型普遍依赖基于知识的思维模式,却缺乏对视觉线索的深度校验与再思考能力,导致在复杂场景下频繁出错。
为解决这一难题,来自中科院自动化研究所紫东太初大模型研究中心的研究者提出 GThinker,一个旨在实现通用多模态推理的新型多模态大模型。
GThinker 的核心在于其创新的「线索引导式反思(Cue-Guided Rethinking)」模式,它赋予了模型在推理过程中主动校验、修正视觉理解的能力。
通过精心设计的两阶段训练流程,GThinker 在极具挑战性的 M³CoT 综合推理基准上取得了超越了最新的 O4-mini 模型,并在多个数学及知识推理榜单上展现出 SOTA 性能,证明了该方法的有效性和泛化能力。目前,论文、数据及模型均已开源。

论文链接:https://arxiv.org/abs/2506.01078
项目地址:https://github.com/jefferyZhan/GThinker
开源仓库:https://huggingface.co/collections/JefferyZhan/gthinker-683e920eff706ead8fde3fc0
慢思考的瓶颈:
当模型在通用场景「视而不见」
当前,无论是开源的 Qwen2.5-VL,还是闭源的 GPT-4o,多模态大模型的能力边界正在被不断拓宽。尤其在引入了思维链(CoT)等慢思考策略后,模型在数学、科学等逻辑密集型任务上的表现得到了显著增强。
然而,这些进步并未完全转化为在通用多模态场景下的推理能力。与拥有明确答案和严格逻辑结构的数理任务不同,通用场景(如理解一幅画的寓意、分析复杂的日常情景)往往涉及:
高度的视觉依赖:答案强依赖于对图像中多个、甚至有歧义的视觉线索的正确解读。
复杂的推理路径:没有固定的解题范式,需要模型根据具体问题灵活组织推理步骤。
现有方法,无论是基于结构化 CoT 的,还是基于结果奖励强化学习的,都存在明显的局限性。它们在推理中一旦对某个视觉线索产生误判,往往会「一条道走到黑」,缺乏中途 「回头看」、修正认知偏差的机制。

现有主流多模态推理方法的特点与局限性
GThinker:
从 「思维链」 到 「再思考链」
为了打破这一瓶颈,研究团队提出了 GThinker,其核心是一种全新的推理模式 ——「线索引导式反思」(Cue-Guided Rethinking)。该模式将推理过程升级为一种更接近人类思维的 「思考 - 反思 - 修正」 闭环,它不强制规定僵化的推理结构,而是要求模型在自由推理后,对关键视觉线索进行一次系统性的回溯验证。
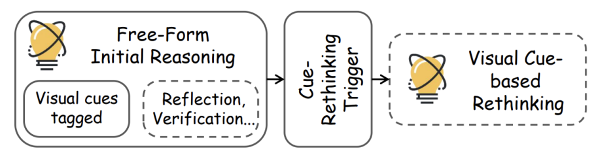
Cue-Rethinking核心流程,虚线框代表可能进行
整个过程分为三个阶段:
1. 自由初始推理:模型根据问题和图像内容,自由地进行一步步推理,同时使用 <vcues_*> 标签标记出其所依赖的关键视觉线索。
2. 反思触发:在初步推理链完成后,一个反思提示(如 「Let's verify each visual cue and its reasoning before finalizing the answer.」)被触发,引导模型进入基于再思考阶段。
3. 基于视觉线索的反思:模型逐一回顾所有标记的视觉线索,检查其解释是否存在不一致、错误或遗漏。一旦发现问题,模型会修正或补充对该线索的理解,并基于新的理解重新进行推理,最终得出结论。

GThinker推理模式示例
以上图为例,GThinker 在初步推理中可能将图形误判为 「螃蟹」。但在再思考阶段,它会发现 「红色三角形更像虾头而非蟹身」、「蓝粉组合更像虾尾而非蟹钳」,从而修正整个推理路径,最终得出正确答案 「虾」。这种机制使得 GThinker 能够有效处理有歧义或误导性的视觉信息,极大地提升了推理的准确性。
两阶段训练法:
如何教会模型进行再思考?
为了让模型内化这种强大的反思能力,GThinker 设计了一套环环相扣的两阶段训练框架。

GThinker 整体训练流程示例图
模式引导冷启动
不同于数理领域在预训练后自然涌现的反思能力,单纯依靠来结果奖励强化学习 「探索」 出如此复杂的再思考行为,不仅成本高昂且效率低下。因此,GThinker 首先通过监督微调的方式,为模型 「冷启动」 构建基于视觉线索的再思考能力。
为此,首先通过「多模态迭代式标注」构建了一个包含 7K 高质量冷启动样本数据集:利用 GPT-4o、O1、O3 等多个先进模型的互补优势,对覆盖通用、数学、科学三大领域的复杂问题进行迭代式地推理和标注,生成了包含高质量再思考路径的训练数据。
在训练时,GThinker 采用「模式引导选择性格式化」策略,仅对那些基座模型会产生视觉误判的样本应用完整的 「反思链」 格式,其余则保留为标准推理格式。这使得模型能够学会在 「需要时」才进行反思,而非机械地执行。
激励强化学习
在掌握 「如何思考」 以及基于视觉线索进行 「再思考」 的能力基础上,GThinker 进一步引入基于可验证奖励的强化学习方法,设计混合奖励机制并构建覆盖多种推理类型的多场景训练数据,以持续激励模型在多样化任务中进行主动探索,从而实现思维模式的跨场景泛化迁移。
多场景数据构建:广泛收集开源推理数据,并通过 embedding 聚类的方式进行均衡和多样性采样,从中精选包含约 4K 条多场景、多任务的强化学习训练数据集,为泛化能力的提升提供数据保障。
DAPO 训练:相较于 GRPO,DAPO 采用动态采样的方式,保证 batch 样本的有效性,并应用无 KL 和 clip higher 等策略,更适用于长链思考和探索,使模型学会在不同场景下选择最优推理方式。

混合奖励计算:针对选择题、数学题等常见任务类型,分别采用精确匹配、Math-Verify 工具校验的方式计算奖励,对于通用场景下常见的开放式简答题,通过加入格式化响应让模型回答归纳到短语或单词的形式,以应用精确匹配的计算方式,从而确保了奖励信号的准确性和进一步拓展支持任务的多样性。
结果
在复杂、多步及多领域的多模态推理基准 M3CoT 上,GThinker 在多个场景的测试中超过当前先进的开源多模态推理模型及 O4-mini。

在通用场景(MMStar、RealWorldQA)、多学科场景(MMMU-Pro)及数学基准测试中,GThinker 实现了优于或不逊于现有先进模型的表现,证明了 GThinker 所学的再思考能力并未造成 「偏科」,而是实现了整体通用能力提升。
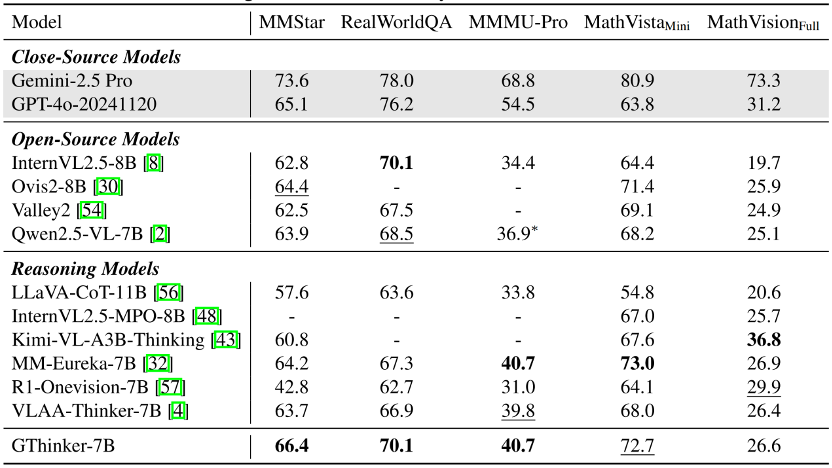
尽管 GThinker 的数据均为复杂推理任务构建,但经过这一方法及数据的训练后,当前最领先的开源模型依然能够在通用指标上进一步提升。研究团队选取了 OpenCompass 闭源多模态榜单中 10B 规模下最新排名前三的开源模型,在学术榜单上进行测试。结果显示,GThinker 在这三款模型上均带来约 1 个百分点左右的平均性能提升,进一步印证了其方法的有效性与泛化能力。

Demo



© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







